2023 年 408 真题
选择题
选择题答案速对
| No. | Ans | No. | Ans | No. | Ans | No. | Ans | No. | Ans |
|---|---|---|---|---|---|---|---|---|---|
| 1 | D | 2 | C | 3 | A | 4 | B | 5 | A |
| 6 | B | 7 | B | 8 | B | 9 | C | 10 | C |
| 11 | D | 12 | C | 13 | A | 14 | A | 15 | C |
| 16 | B | 17 | A | 18 | B | 19 | C | 20 | D |
| 21 | D | 22 | C | 23 | D | 24 | A | 25 | C |
| 26 | D | 27 | C | 28 | D | 29 | B | 30 | C |
| 31 | B | 32 | D | 33 | D | 34 | C | 35 | B |
| 36 | C | 37 | D | 38 | A | 39 | B | 40 | D |
数据结构
1
下列对顺序存储的有序表(长度为 n)实现给定操作的算法中平均时间复杂度为 O(1) 的是( )。
线性表的顺序存储结构采用一组地址连续的存储单元依次存储线性表的数据元素。特点是逻辑上相邻的数据元素在物理位置上相邻。线性表顺序存储结构是一种随机存取的存储结构,设线性表的每个元素占 L 个存储单元,第一个元素 的存储地址是 LOC( ),则任意元素 的 LOC(ai)=LOC( )+(i-1)*L。因此获取第 i 个值的算法为常量阶 O(1)。
2
现有非空双向链表 L,其结点结构为:
prev 是指向前直接前驱结点的指针,next 是指向直接后继结点的指针。若要在 L 中指针 p 所指向的结点(非尾结点)之后插入指针 s 指向的新结点,则在执行了语句序列: s->next=p->next; p->next=s,后,还要执行( )。
主要考察双链表的插入操作,解决这类问题可在纸上画出具体的双链表进行模拟。因为
s->next 已经赋值为 p 的后一个结点,同时 p->next 指针已经赋值为 s。所以只需要处理s->next->prev 和 s->next->prev 的赋值,s->prev 需要指向 p,s-next->prev 需要指向 s。因为p->next 和 s 指向同一个结点,所以可以用 p->next 代表 s。故本题的正确选项为 C。3
若采用三元组表存储结构存储系数矩阵 M。则除三元组外,下列数据中还需要保存的是( )。
I. M 的行数
II. M 中包含非零元素的行数
III. M 的列数
IV. M 中包含非零元素的列数
存储稀疏矩阵 M,三元组表 的表项存储了行 row、列 col、值 value 三种信息,除此之外,我们还需要知道矩阵 M 的规模 rows × cols,即 M 的行数 rows 和 M 的列数 cols,这个信息应该直接给出。当我们需要某个位置的元素,可以先根据 M 的行数和列数判断是否越界,如果没有越界,在三元组进行查找,如果三元组没有保存对应位置的值代表矩阵中该位置的值为 0。本题答案选 A。
4
在有 6 个字符组成的字符集 S 中,各个字符出现的频次分别为 3, 4, 5, 6, 8, 10,为 S 构造的哈夫曼树的加权平均长度为( )
5
已知一棵二叉树的树形如图,若其后序遍历为 f,d,b,e,c,a,则其先序序列为( )。
如下图所示。对于后序序列 fdbeca,a 为树节点的根,因此在序号 1 中,a 首先进行绘制。同时,a 节点的左子树有 4 个节点,右子树有 1 个节点,因此 fdbe 属于左子树,c 节点属于右子树,所以我们在序号 2 的树中,填充 c。a 结点左子树的后序遍历序列为 fdbe,代表 e 为左子树的根节点,因此在序号 3 的树中,填充 e。同理 e 节点的左子树有两个节点,右子树有一个节点,因此 fdb 属于左子树,e 属于右子树,在序号 4 的树中,我们填写 b。e 的左子树的后序遍历序列为 fd,则 d 为子树的根节点,因此在序号 5 的树中,我们填充 d,最后在序号 6 的图中,填充 f。先序序列为 a,e,d,f,b,c。本题答案选 A。
6
已知无向连通图 G 中各边的权值均为 1,下列算法中,一定能够求出图 G 中从某顶点到其余各个顶点最短路径的是( )。
I. 普利姆算法
II. 克鲁斯卡尔算法
III. 图的广度优先搜索
普里姆算法和克鲁斯卡尔算法是用于解决最小生成树问题的算法,它们并不直接适用于求解最短路径问题。广度优先遍历 (BFS) 是一种图遍历算法,可以用于求解单源最短路径问题。在权值均为 1 的情况下,BFS 算法从给定的起始顶点开始遍历,按照层级顺序逐步扩展,每次扩展一层。这样,当 BFS 遍历到目标顶点时,它所经过的边数就是从起始顶点到目标顶点的最短路径长度。因此,BFS 算法可以用于求解图 G 中从某个顶点到其余各个顶点的最短路径。本题答案选 B。
7
下列关于非空 B 树的叙述中,正确的是( )
I. 插入操作可能增加树的高度
II. 删除操作一定会导致叶结点的变化
III. 查找某关键字一定是要查找到叶结点
IV. 插入的新关键字最终位于叶结点中
在 B 树 中,插入 操作可能导致节点分裂。如果根节点已满,插入新键会触发根节点分裂,生成一个新的根节点,从而增加树的高度。因此,插入操作确实可能(但不一定)增加树的高度。选项 I 正确。
删除 操作可能涉及以下情况:
- 删除的键在叶子结点:直接从叶子结点移除该键,导致叶子结点内容变化。
- 删除的键在非叶子结点:B 树会用前驱或后继键(通常位于叶子结点)替换该键,然后删除前驱或后继键。这仍然会导致叶子结点的变化。
- 删除后触发合并或借键:如果删除键后某个节点键数低于最小要求(通常 ⌈m / 2⌉ − 1),可能需要从兄弟节点借键或与兄弟节点合并。这些操作可能涉及叶子结点(例如,合并两个叶子结点或调整叶子结点的键)。
在所有删除场景中,无论是直接删除键还是通过替换、合并、借键,操作最终都会影响叶子结点(键的移除或调整发生在叶子结点)。选项 II 正确。
查找关键字并不一定需要查找到叶子结点。例如,如果目标键位于根节点或中间节点,查找会在这些非叶子结点停止。选项 III 错误。
新关键字在 B 树中开始总是被插入到叶子结点中,但是可能随着分裂上溢到非叶子结点,选项 IV 错误。
8
对含有 600 个元素的有序顺序表进行折半查找,关键字之间的比较次数最多是( )。
在含有 600 个元素的有序表进行折半查找时,其关键字比较次数最多的情况发生在目 标元素不在表中的情况下。在这种情况下,折半查找会进行到最后一步,直到左边界和右边界 相遇。因此,关键字比较次数最多的情况是在查找过程中遍历整个表的情况。在进行折半查找 时,每次比较会将查找范围缩小一半,直到找到目标元素或确定目标元素不在表中。对于 600 个元素的有序表,因为 ,采用 9 次遍历并不能查找完成,因此需要 10 次查找。 本题答案选 B。
9
现有长度为 5,初始为空的散列表 HT,散列表函数 H(k) = (k+4) % 5 用线性探查再散列法解决冲突。若将关键字序列 2022,12,25 依次插入 HT 中,然后删除关键字 25,则 HT 中查找失败的平均查找长度( )。
线性探测再散列法中删除一个关键字会导致后面的关键字无法通过线性探测找到正确 的位置。当删除一个关键字时,为了保持散列表的连续性,通常会将后续的关键字向前移动填 充空缺,这样后续的查找操作才能继续正确地找到它们。然而,如果删除的是一个位于中间位 置的关键字,后面的关键字需要依次向前移动,这会导致删除操作的时间复杂度较高,因为需 要移动大量的关键字。为了解决删除操作中的位置依赖性问题,可以使用删除标记来表示一个 位置上的关键字已被删除。
如下表所示,查找失败的平均查找长度为 (1+3+2+1+2)/5=1.8。本题答案选 C。
| 地址 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| Key | 2022 | 12 | 25 (delete) | ||
| 查找失败次数 | 1 | 3 | 2 | 1 | 2 |
10
下列排序算法中,不稳定的是( )
I. 希尔排序
II. 归并排序
III. 快速排序
IV. 堆排序
V. 基数排序
参考 排序总结,快速排序在每一轮划分时,通常选择一个枢轴元素将序列分成两部分,并且在交换 元素时可能改变相同关键字元素的相对顺序,因此不是稳定的排序算法。堆排序使用堆数据 结构进行排序,其中在建堆和调整堆的过程中,元素的交换可能导致相同关键字元素的相对 顺序发生改变,因此堆排序也不是稳定的排序算法。希尔排序是基于插入排序的一种改进算 法,它通过将待排序的序列划分成若干个较小的子序列进行插入排序,然后逐步缩小子序列 的间隔,最终完成整个序列的排序。由于希尔排序是通过跳跃式的插入排序进行排序的,相 同关键字的元素可能会跨越较大的间隔进行比较和交换。这种跨越较大间隔的比较和交换可 能导致相同关键字的元素的相对顺序发生改变,因此希尔排序是不稳定的排序算法。因此不 稳定的排序算法有希尔排序、快速排序、堆排序。本题答案选 C。
11
使用快速排序算法对数据进行升序排序,若经过一次划分后得到的数据序列是 68, 11, 70, 23, 80, 77, 48, 81, 93, 88,则该次划分的轴枢( )。
在 快速排序 中,划分过程通常选择一个枢轴元素来将待排序序列划分为两个子序列。因为是升序排序,所以枢纽元素的前半个子序列的值需要都小于枢轴值,后半个子序列的值需要都大于枢轴值。分别从每个选项来看,A 选项的枢轴值为 11,前半个子序列的值只有68,大于枢轴值 11,不符合。B 选项的枢轴值为 70,前半个子序列都小于 70,但后半个子序列存在 23 和 48 小于 70,不符合。C 选项的枢轴值为 80,前半个子序列的值都小于 80,但是后半个子序列存在 48 小于 80,不符合。D 选项的枢轴值为 81,81 前面的元素都小于 81,81 后面的元素都大于 81,符合。因此本题的正确选项为 D。
组成原理
12
若机器 M 的主频为 1.5Ghz,在 M 上执行程序 p 的指令条数为 次方,p 的平均 CPI 为 1.2,则 p 在 M 上的指令执行速度和用户 CPU 时间分别为( )
p 每条指令平均需要 个时钟周期,机器 M 的主频为 1.5GHZ 代表每秒共有 个时钟周期,则每秒能执行 1.5G / 1.2 = 1.25G 条指令。执行 p 程序共需要 个时 钟周期,每秒有 个时钟周期,则 个时钟周期共需要 。所以 本题的正确答案为 C。
13
若 short 型变量 x = -8190,则 x 的机器数为( )
机器数是计算机内部用来表示和存储数值的二进制形式。对于有符号的 short 型变量, 通常采用 16 位 补码 表示法。对于给定的 short 型变量 x=-8190,我们需要将其转换为二进制的补码表示。首先,将数值 8190 转换为二进制形式:8190 = 0001 1111 1111 1110B,然后取其二 进制补码(负数取反后加 1),补码为 1110 0000 0000 0010B,转化为 16 进制为 E002H。因此 正确选项为 A。
14
已知 float 型变量用 IEEE754 单精度浮点数格式表示。若 float 型变量 x 的机器数为 8020 0000H,则 x 的值( )
本题考查浮点数表示的 异常值,给定的机器数为 8020 0000H,表示一个 32 位的二进制数。我们需要将其转换为 float 型变量的值。8020 0000H = 1000 0000 0010 0000 0000 0000 0000 0000B。根据 IEEE754 单精度 浮点数格式,首位表示符号位,接下来的 8 位表示指数部分,剩下的 23 位表示尾数部分。拆 分该二进制表示,我们得到以下部分,符号位:1(表示负数),指数部分:00000000B(十进制值 为 0)。尾数部分:010 0000 0000 0000 0000 0000B。本题考查的点为 IEEE 754 单精度点数的表 示,因为指数部分为 0,尾数部分不为 0,所以为非规格化的表示,所以尾数部分的形式为 0.M 不是 1.M,同时指数部分是 -126,而不是 -127,则真值为 ,正确答案为 A 选项。
15
某计算机的 CPU 有 30 根地址线,按字节编址,CPU 和主存芯片连接时,要求主存芯片占满所有可能存储地址空间,并且 RAM 区和 ROM 区所分配的容量大小比为 3:1,若 RAM 在连续低地址区,ROM 在连续高地址区,则 ROM 的地址范围( )
由于 CPU 有 30 根地址线,每根地址线可以表示 2 个不同的状态(0 或 1)。因此,CPU 的地址线共有 个不同的地址。根据 RAM 和 ROM 的分配比,RAM 区占据整个地址空间的 3/4,而 ROM 区占据剩下的 1/4,我们可以选取高位的两根地址线,00、01、10 分配给连续低 地址的 RAM,则高位只剩下 11 可以分配,所以可以分配的地址范围为 110…00(28 个 0)~ 11…1 (30 个 1),十六进制表示为 300000000H ~ 3FFFFFFFFH。故本题的正确选项为 C。
16
已知 x、y 为 int 类型,当 x=100,y=200 时,执行 x-y 指令的到的溢出标志 OF 和借位标志 CF 分别为 0,1,那么当 x=10,y=-20 时,执行该指令得到的 OF 和 CF 分别是( )
int 类型在计算机中以补码形式表示,因此,x(10)的二进制表示为 0000 0000 0000 0000 0000 0000 0000 1010B,y(-20)的二进制表示为 11111111 11111111 1111 1111 11101100。
OF 和 CF 是 CPU 中 标志寄存器 的标志位。CF 表示无符号整数运算时的进位/借位,因此计算 CF 的时候,需要把和 x 和 y 当成无符号数进行计算,因为 x 不够减 y,所以 CF = 1。计算 OF 的时候,需要把和 x 和 y 当成有符号数进行计算,x-y=30,不超过 int 的最大值,不会产生溢出,所以 OF=0。所以本题的正确选项为 B。
17
某运算类型指令中有一个地址码为通用寄存器编号,对应通用寄存器中存放的是操作数或操作数地址,CPU 区分两者的依据是( )
在指令中,使用不同的操作码来区分寄存器中存放的是操作数还是操作数的地址指令会有明确的 寻址方式,指示使用寄存器中的内容作为操作数或操作数地址。当 CPU 在执行指令时会根据指令中的寻址方式字段来正确解析寄存器中的内容,并根据需要进行相应的操作。所以本题的正确选项为 A。
18
数据通路由组合逻辑元件(操作元件)和时序逻辑元件(状态元件)组成。下列给出的元件中,属于操作元件的是( )。
I. 算术逻辑部件(ALU)
II. 程序计数器(PC)
III. 通用寄存器组(GPRs)
IV. 多路选择题(MUX)
组合逻辑元件 是那些仅由组合逻辑电路组成的元件,其输出仅取决于当前的输入,而不受存储器或时钟信号的影响。算术逻辑部件 ALU 和多路选择器 MUX 都属于组合逻辑元件,它们的输出仅由当前输入决定。
程序计数器 PC 和通用寄存器是时序逻辑元件,也称为状态元件。它们的输出不仅取决于当前输入,还受存储器或时钟信号的影响,并且具有状态或存储功能。因此本题选 B。
19
在采用“取指、译码/取数、执行、访存、写回”5 段流水线的 RISC 处理器中,执行如下指令序列(第一列为指令序号),其中 s0、s1、s2、s3 和 t2 表示寄存器编号。
I1 add s2, s1, s0 // R[s2] ← R[s1] + R[s0]
I2 load s3, 0(s2) // R[s3] ← M[R[s2] + 0]
I3 beq t2, s3, L1 // if R[t2] = R[s3] jump to L1
I4 addi t2, t2, 20 // R[t2] ← R[t2] + 20
I5 L1:
若采用转发(旁路)技术处理数据冒险,采用硬件阻塞方式处理控制冒险,则在 I1~I4 执行过程中,发生流水线阻塞的指令有( )。
在以下指令序列中:
- I1:写寄存器
R[s2] - I2:使用
R[s2]计算访存地址 - I3:使用
R[s3]进行比较跳转 - I4:紧跟在
beq指令之后执行
- I2 与 I1 之间:写后读数据冒险(RAW Hazard)
指令 I1 将结果写入寄存器 R[s2],但这个值直到 I1 的 写回(WB)阶段 才会更新。而 I2 在其 执行(EX)阶段 就需要用到 R[s2] 来计算访存地址,因此存在写后读的数据冒险。
幸运的是,I1 在 EX阶段末尾 就已生成结果并存储在 EX→M 流水段寄存器中。此时如果使用 旁路转发,可以直接将这个值从流水段寄存器中转发到 I2 的 ALU 输入端,避免等待 WB 阶段,从而解决了这个 RAW 冒险。
- I3 与 I2 之间:装入-使用 数据冒险(Load-Use Hazard)
I2 是一条 load 指令,它需要从内存中将数据装入寄存器 R[s3]。而 I3 在它的 EX 阶段就要用到 R[s3] 的值。如果像前面那样尝试用旁路技术从 I2 的 EX→M 寄存器转发数据,会失败——因为此时的数据尚未从内存中读出。
只有等到 I2 的 访存(M)阶段结束,数据才真正从内存中取回,存放在 M→WB 流水段寄存器。因此,仅靠转发线路无法解决装入-使用冒险。
需要采取的办法是:对 I3 硬件阻塞一个周期,等待 I2 的 M 阶段完成,然后通过转发将 R[s3] 的新值从 M→WB 段寄存器送入 I3 的 ALU,以确保其操作正确。
- I4 与 I3 之间:控制冒险(Control Hazard)
I3 是一条 beq 分支指令。该指令在 EX 阶段比较寄存器值,在 M 阶段才判断跳转是否成立并更新 PC(程序计数器)。因此,在得知是否跳转前,I4 的取指(IF)阶段必须等待 I3 的 M 阶段完成。
这就导致 I4 的执行被 阻塞 3 个时钟周期,以确保其是否被执行是基于正确的控制流判断。
最终,系统采用 硬件阻塞机制 来处理上述数据和控制冒险,下图展示了指令执行过程中各阶段的具体安排:
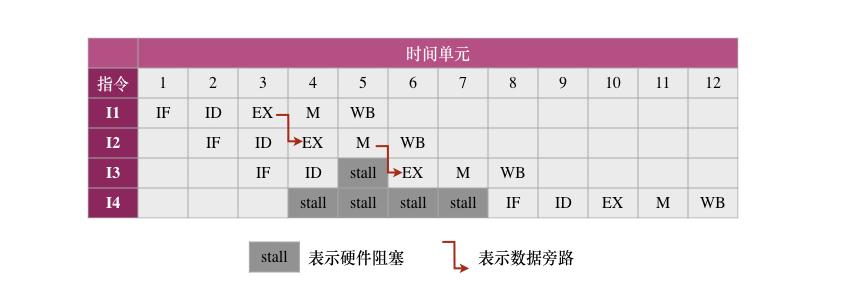
20
某存储器总线宽度为 64 位,总线时钟频率为 1GHZ,在总线上传输一个数据或地址需要一个的时钟周期,不支持突发传送方式,若通过该总线连接 CPU 和主存,主存每次准备一个 64 位数据需要 6ns,主存块大小为 32B,则读取一个主存块需要的时间为( )。
存储总线的宽度为 64 位,代表每次数据传送可以传送 64bit 的数据。总线时钟频率位 1GHZ,代表 1s 可以传送 1G 次,即 10⁹ 次/s,所以每个时钟周期为 10⁻⁹s = 1ns。具体步骤为: CPU 通过地址线传输地址花费 1ns,主存准备数据 6ns,主存传输数据到 CPU 花费 1ns,共 8ns, 因为 32B 的数据在总线宽度为 64 位的总线上,需要传输 (32*8bit) / 64bit = 4 次,因此读取一个 主存块的时间为 4×8ns=32ns。所以本题的正确选项为 D 选项。
21
下列关于硬件和异常/中断关系的叙述中,错误的是( )。
异常通常指内部中断,是指令执行错误或中断指令产生的内部中断,在指令执行过程 中被检测,因此选项 A 正确。外部中断指硬件中断,在指令执行完毕后,CPU 会检查中断请 求信号,如果有中断请求发生,则进行中断响应,暂停当前的任务,保存现场并处理中断,因 此,选项 B,C 正确。外部设备通过中断控制器向 CPU 发出中断请求信号而不是中断结束信 号,选项 D 错误。
22
下列关于 I/O 控制方式的叙述中,错误的是( )。
在 DMA(直接内存访问)方式下,CPU 并不直接执行 DMA 传送程序进行 IO 操作。 DMA 是一种特殊的 I/O 控制方式,它允许外设设备直接与主存进行数据传输,数据传输过程 是由硬件(DMA 控制器)完成的,而无需 CPU 的干预,所以 C 选项的描述错误。本题需要选 择错误的选项,因此本题的答案为 C。
操作系统
23
与宏内核操作系统相比,下列特征中微内核操作系统具有的是( )。
Ⅰ. 较好的性能
Ⅱ. 较高的可靠性
Ⅲ. 较高的安全性
Ⅳ. 较强的可扩展性
参考微内核和宏内核, 选项 II 较高的可靠性:微内核操作系统将核心功能模块化,将部分操作系统功能移出 内核,以减少内核的复杂性和错误的影响范围,从而提高系统的可靠性,由于微内核中只包含 最基本的功能,因此可以更容易地对其进行验证和测试,减少错误的概率。选项 III 较高的安 全性:微内核操作系统通过将一些非核心功能移出内核,以降低系统的攻击面,只有核心的、 必要的功能位于内核中,而其他的服务和驱动程序则在用户空间运行,减少了恶意代码对内核 的直接访问,这有助于提高系统的安全性,并减少潜在的漏洞。选项 IV 较强的可扩展性:微 内核操作系统的设计使得新增功能或服务更容易添加到系统中。由于非核心功能运行在用户空 间,可以通过插件或模块的形式进行扩展,而无需对内核进行大规模的修改,这使得微内核操 作系统更具有灵活性和可扩展性。微内核操作系统采用模块化设计,将一部分功能移至用户空 间,这就需要通过进程间通信(IPC)机制来实现内核与用户空间的交互。这种通信会引入额 外的开销,包括上下文切换、数据拷贝等,从而影响系统的性能。所以选项 I 不是微内核操作 系统所具有的特点,正确的选项为 II,III,IV,选择 D 选项。
24
在操作系统内核中,中断向量表适合采用的数据结构是( )。
在操作系统内核中,中断向量表 适合采用的数据结构是数组(选项 A)。中断向量表 是一种用于存储中断处理程序入口地址的数据结构,它以中断号作为索引,将中断号映射到相 应的中断处理程序入口地址。由于中断号是一个固定的范围(例如,0~255)采用数组可以实 现快速的索引和访问,具有较高的效率。使用数组可以直接根据中断号计算出对应的数组索引 而不需要遍历链表或队列来查找对应的处理程序入口地址,从而提高中断处理的效率。所以本 题的正确选项为 A。
25
某系统采用页式存储管理,用位图管理空闲页框。若页大小为 4 KB,物理内存大小为 16 GB,则位图所占空间的大小是( )。
物理内存大小为 ,每页大小为 ,因此物理内存总共包含的页框数为 。位图需要管理每个页框的空闲状态,因此位图的位数应该等于物理 内存中页框的数量。每个位表示一个页框的空闲状态,所以位图所占空间大小应为 ,因此,位图所占空间的大小为 ,选项 为正确答案。
26
下列操作完成时,导致 CPU 从内核态转为用户态的是( )。
来看每个选项的含义和状态切换:
对于 A 选项,阻塞过程属于进程状态切换,不直接涉及CPU模式转换。
对于 B 选项,执行 CPU 调度属于内核调度器行为,通常保持在内核态。
对于 C 选项,唤醒进程属于进程管理操作,不直接触发模式切换
对于 D 选项,当用户程序需要访问特权指令或执行需要操作系统提供的服务时,它会通过 系统调用 请求进人内核态。在系统调用期间,CPU 会切换到内核态执行相应的内核代码来满足用户程序的需求。一旦系统调用执行完毕,CPU 会从内核态返回到用户态继续执行用户程序。所以,执行系统调用是导致 CPU 从内核态转为用户态的关键操作。所以该题的正确选项为 D 选项。
27
下列出当前线程引起的事件或执行的操作中,可能导致该线程由执行态变为就绪态的是( )。
参考 状态转化, B 缺页异常:当线程访问的页面不在内存中时,会触发缺页异常,处理缺页异常时, 线程可能需要等待操作系统将所需页面加载到内存中,这会导致线程由执行态变为阻塞态。C 主动让出 CPU:线程可以通过主动让出 CPU 的方式,将自身的执行权限交给其他就绪态的线 程。这会导致线程由执行态变为就绪态。D 执行信号量的 wait() 操作:在多线程编程中,信 号量通常用于线程间的同步和互斥。当一个线程执行信号量的 wait() 操作时,如果信号量的 计数值不满足条件,线程会进入阻塞状态,从执行态变为阻塞态。键盘输入(选项 A)通常不 会直接导致线程状态变化,它可能触发其他事件或操作,进而影响线程的状态。所以本题的正 确选项为 C 选项。
28
对于采用虚拟内存管理方式的系统,下列关于进程虚拟地址空间的叙述中,错误的是( )。
A:虚拟地址空间是一个进程所使用的虚拟内存地址的集合,每个进程都有自己的虚拟 地址空间,这个空间是独立于其他进程的,每个进程都认为自己在访问整个系统的内存空间, 但实际上,它们只访问到了被分配给它们的部分内存。B:malloc 返回虚拟地址,当调用 malloc 时,分配出来的空间,只是在虚拟内存中是连续的,从实际的物理空间到虚拟内存空间还有一 个映射的关系。C:不同的段访问权限可以是不同的。一般来说,代码段可读可执行,并且只 能在特权模式下执行,但是不可写;数据段可以读写,不能执行。D:主存和硬盘的大小不直 接影响虚拟地址的实际大小,虚拟地址的大小由底层的虚拟内存管理机制和操作系统定义决定, 通常在不同的系统中有所不同。虚拟地址空间的大小可以在操作系统中进行配置和限制,而主 存和硬盘的大小影响的是实际可用的物理内存和存储容量,而非虚拟地址的大小,虚拟内存管 理机制通过将虚拟地址映射到物理内存或硬盘上的页面来提供更大的虚拟地址空间。因此,主 存和硬盘的大小可以影响实际可用的虚拟内存空间的大小,但并不直接决定虚拟地址的大小。 所以本题的答案为 D 选项。
29
进程 P1、P2 和 P3 进入就绪队列的的时刻,优先值(越大优先权越高)以及 CPU 的执行时间如下表所示。
| 进程名 | 进入就绪队列的时刻 | 优先级 | CPU 执行时间 |
|---|---|---|---|
| P1 | 0 ms | 1 | 60 ms |
| P2 | 20 ms | 10 | 42 ms |
| P3 | 30 ms | 100 | 13 ms |
系统采用基于优先权的抢占式 CPU 调度算法,从 0ms 时刻开始进行调度,则 P1、P2 和 P3 的平均周转时间为( )。
具体的调度表如下图所示。周转时间 = 完成时间 - 到达时间,进程 1 的周转时间为 115ms-0ms=115ms,进程 2 的周转时间为 75ms-20ms=55ms,进程 3 的周转时间为 43ms- 30ms=13ms。平均周转时间为 (115+55+13)/3=61ms。所以该题的答案为 B 选项。
30
进程 R 和 S 共享数据 data,若 data 在 R 和 S 中所在页的页号分别为 p1 和 p2,两个页所对应的页框号分别为 f1 和 f2,则下列叙述中,正确的是( )。
对于进程 R 和 S 共享数据 data 的情况,它们在各自的虚拟地址空间中有自己的页表, 虚拟地址到物理地址的转换是通过页表完成的。因此,对于同一虚拟地址,R 和 S 的页号 p1 和 p2 可能不相等,因为它们对应于各自的页表中的不同页项。然而,当数据 data 在内存中时, 它被映射到物理内存的同一页框中,即 f1 和 f2 是相等的,这是因为共享的数据页被映射到相 同的物理页框中,不同进程的虚拟地址映射到相同的物理地址。所以本题的正确选项为 C 选项。
31
若文件 F 仅被进程 P 打开并访问,则当进程 P 关闭 F 时,下列操作中,文件系统需要完成的是( )。
索引节点是指文件系统中的一种数据结构,每个索引节点保存了文件系统中的一个文 件系统对象的元信息数据,但不包括数据内容或者文件名。内存索引节点是存放在内存中的索 引节点,文件被打开时,需要将磁盘索引节点复制到内存索引节点中。因此本题进程 P 关闭 F 时,需释放 F 的索引节点所占的内存空间。所以该题的正确答案为 B 选项。
32
下列因素中,设备分配需要考虑的是( )。
Ⅰ. 设备的类型
Ⅱ. 设备的访问权限
Ⅲ. 设备的占用状态
Ⅳ. 逻辑设备与物理设备的映射关系
I.设备类型:不同类型的设备有不同的特性和接口,需要根据设备类型进行适当的分 配和管理。II.设备使用状态:需要考虑设备的当前使用状态,即设备是否已经被其他进程占用 或者正在执行某个操作,设备分配时需要避免资源冲突。III.逻辑设备和物理设备的映射:在系 统中,逻辑设备和物理设备之间存在映射关系。逻辑设备是用户程序或操作系统中对设备的抽 象表示,而物理设备是实际的硬件设备。设备分配需要确保逻辑设备与物理设备之间的正确映 射。IV.进程对设备的访问权限:不同的进程可能对设备的访问有不同的权限要求。设备分配时 需要考虑进程的访问权限,确保只有具有适当权限的进程能够访问和使用设备。因此,正确的 选项是 I、II、III、IV。本题的正确选项为 D。
计算机网络
33
如图,2 段链路的数据传输速率为 100Mbps,时延带宽积(即单向传播时延*带宽)均为 1000bit。若 H1 向 H2 发送 1 个大小为 1MB 的文件,分组长度为 1000B,则从 H1 开始发送时刻起到 H2 收到文件全部数据时刻止,所需的时间至少是(注: )?
| 参数 | 计算 | 结果 |
|---|---|---|
| 链路带宽 | — | |
| 时延带宽积 | 题设给定 | |
| 传播时延 | 0.01 ms | |
| 分组大小 | — | |
| 发送时延 | 0.08 ms | |
| 分组数量 | 1000 |
- 发送阶段
- 第 1 个分组: ms 发送完。
- …
- 第 1000 个分组: ms 发送完。
因此,最后 1 位比特离开 H1 的时刻为 。
- H1 → R 传播
单向传播时延
ms
- R 转发(序列化)
路由器必须将该分组重新发送一次,耗时仍为
ms
- R → H2 传播
再次经过链路传播时延
ms
所以答案选择 D。
34
某无噪声理想信道带宽为 4MHz,采用 QAM 调制,若该信道的最大数据传输率是 48Mbps,则该信道采用的 QAM 调制方案是()
对于无噪声理想信道,信道的最大数据传输率可以通过 奈奎斯特定理 计算,最大数据传输的次数为 2×4MHz=8MHz,代表每秒传输 8M 次,因为最大的数据传输率为 48Mbps,所以每次需要传输的比特数量为 48Mbps/8MHz=6 位,所以每次传输的数据量位 6 比特,那么采用的 QAM 调制方案为 26=64,即采用 QAM-64 的方案。本题的正确选项为 C。
35
假设通过同一信道,数据链路层分别采用停等协议、GBN 协议和 SR 协议(发送窗口和接收窗口相等)传输数据,三个协议数据帧长相同,忽略确认帧长度,帧序号位数为 3 比特。若对应三个协议的发送方最大信道利用率分别是 U1、U2 和 U3,则 U1、U2 和 U3 满足的关系是( )
停等协议的 信道利用率 公式为:
GBN 协议和 SR 协议的 信道利用率 公式为:
观察会发现, 项都是相同的,GBN 协议和 SR 协议的信道利用率需要比停等协议的信道利用率多乘上窗口大小(大于等于 1)。得出结论,停等协议的信道利用率 U1 最小,排除 C、D 选项。GBN 协议和 SR 协议的信道利用率主要看窗口大小谁比较大。题目说了帧序号位数为 3 比特,那 GBN 协议的发送窗口的尺寸 ,应满足: 。则发送窗口最大为 。SR 协议的发送窗口的尺寸 ,应满足: ,则发送窗口最大为 。因此 GBN 协议的信道利用率 U2 的最大值要大于 SR 协议的信道利用率 U3。综上所述,答案选择 B 选项。
36
已知 10BaseT 以太网的争用时间片为 51.2us。若网卡在发送某帧时发生了连续 4 次冲突,则基于二进制指数退避算法确定的再次尝试重发该帧前等待的最长时间是( )
基于 指数退避算法,每次发生冲突后,网卡会随机选择一个等待时间,在 到 个时间片之间等待,其中 是当前发生冲突的次数。根据问题描述,发生了连续 次冲 突,即 。那么根据二进制指数退避算法,等待时间将在 到 之间。最长的等待时间即 为 个时间片。计算如下: ,每个时间片的时长为 ,因此最长的等待时间 为 。选择 C 选项。
37
若甲向乙发送数据时采用 CRC 校验,生成多项式为 (即 G=10011),则乙接收到下列比特串时,可以断定其在传输过程中未发生错误的是( )
在 循环冗余码 中:
若接收端将接收到的比特串除以 G(x),余数为 0,则认为“未发生错误”。
即,我们要对每一个选项做模 2 除法(异或除法),看余数是否为 0。
经过计算,可以得到 D 选项余数为 0,所以答案选择 D。
38
某网络拓扑如下图所示,其中路由器 R2 实现 NAT 功能。若主机 H 向 Inernet 发送一个 IP 分组,则经过 R2 转发后,该 IP 分组的源 IP 地址是( )
当 IP 分组经过 网络地址转换(Network Address Translation, NAT)转发时,会发生源 IP 地址转换:NAT 会将源 IP 地址从私有 IP 地址(在局域网内使用的 IP 地址)转换为公共 IP 地 址(在互联网上可路由的 IP 地址)。这是为了隐藏内部网络的真实 IP 地址,使其在公共网络 上不可见。同时给定 IP 地址段为 192.168.0.34/30,它表示一个有 30 位网络前缀的子网。根据 CIDR 表示法,30 表示子网掩码为 255.255.255.252。在这个子网中,可用的 IP 地址如下,网 络地址:192.168.0.32,第一个可用地址:192.168.0.33,最后一个可用地址:192.168.0.34,广 播地址:192.168.0.35。可以分配的源地址为 192.168.0.33 和 192.168.0.34,因为选项中只有 192.163.0.33,所以本题正确答案为选项 A。
39
主机 168.16.84.24/20 所在子网的最小可分配地址和最大可分配地址分别是( )
题目给的主机 168.16.84.24/20 用二进制展开可以得到:168.16.0101 0100.24 可以看到, 网络前缀为前 20 位,主机号为后 12 位。最小可分配地址是主机号为 1 的情况,可以得到最小 可分配地址为 168.16.0101 0000.1 = 168.16.80.1。最大可分配地址是广播地址减 1 的情况,可以 得到最大可分配地址为 168.16.0101 1111.254 = 168.16.95.254。答案选择 B 选项。 IPv4 是 32 位的地址长度,而 IPv6 是 128 位的地址长度,二者相差了 64 位,由于是 二进制表示,所以地址数量相差了 264 倍。因此 I 错误。IPv4 的基本首部有选项字段,因此长 度可变;IPv6 将可选字段移除,变成了扩展首部,但是扩展首部被放在了有效载荷中,因此基 本首部长度是不可变的,II 错误。在完全过渡到 IPv6 之前,IPv4 和 IPv6 并行使用,可以采用 双协议栈技术和隧道技术进行。III 正确。IPv6 首部的 Hop-Limit 表示跳数限制,代表了 IP 数 据报在网络中的最大跳数;而 IPv4 首部的 TTL 字段表示最大寿命,也表示了 IP 数据报在网 络中的最大跳数,如果超出了 TTL,则该 IP 数据报要被丢弃。IV 正确。综上所述,答案选择 D 选项。
40
下列关于 ipv6 和 ipv4 的叙述中,正确的是( )
I. ipv6 地址空间是 ipv4 地址空间的 96 倍
II. ipv4 和 ipv6 的基本首部的长度均可变
III.ipv4 向 ipv6 过渡可以采用双协议栈和隧道技术
IV. ipv6 首部的 Hop-Limit 等价于 ipv4 首部的 TTL 字段
IPv4 是 32 位的地址长度,而 IPv6 是 128 位的地址长度,二者相差了 96 位,由于是二进制表示,所以地址数量相差了 倍。因此 I 错误。
IPv4 的基本首部有选项字段,因此长度可变; IPv6 将可选字段移除,变成了扩展首部,但是扩展首部被放在了有效载荷中,因此基本首部长度是不可变的,Ⅱ错误。
在完全过渡到 IPv6 之前,Pv4 和 Pv6 并行使用,可以采用双协议栈技术和隧道技术进行。Ⅲ 正确。
IPv6 首部的 Hop-Limit 表示跳数限制,代表了 IPv6 数据报在网络中的最大跳数; 而 IPv4 首部的 TTL 字段表示最大寿命,也表示了 IPv4 数据报在网络中的最大跳数, 如果超出了 TTL,则该 P 数据报要被丢弃。V 正确。
综上所述,答案选择 D 选项。
解答题
数据结构
41
已知有向图 G 采用邻接矩阵存储,类型定义如下:
typedef struct { // 图的类型定义
int numVertices, numEdges; // 图中顶点数和有向边数
char VerticesList[MAXV]; // 顶点表,MAXV 为已定义常量
int Edge[MAXV][MAXV]; // 邻接矩阵
} MGraph;
将图中出度大于入度的顶点称为 K 顶点。例如在题 41 图中,顶点 a 和 b 都是 K 顶点。
设计算法 int printVertices(MGraph G) 对给定任意非空有向图 G,输出 G 中所有 K 顶点的算法,并返回 K 顶点的个数。
(1) 给出算法的设计思想。
(2) 根据算法思想,写出 C/C++ 描述,并注释。
42
对含有 n(n > 0)个记录的文件进行外部排序,采用置换 - 选择排序生成初始归并段时需要使用一个工作,工作区中能保存 m 个记录,请回答下列问题,
(1) 如果文件中由 19 个记录,其关键字是 51, 94, 37, 92, 14, 63, 15, 99, 48, 56, 23, 60, 31, 17, 43, 8, 90, 166, 100;当 m=4 时,可以生成几个初始归并段,各是什么?
(2) 对任意的 m 个(n > m > 0),生成的第一个初始归并段的长度最大值和最小值分别是多少?
组成原理
43
已知计算机 M 字长为 32 位,按字节编址,采用请求调页策略的虚拟存储管理方式,虚拟地址为 32 位,页面大小为 4KB;数据 Cache 采用 4 路组相联映射,数据区大小为 8KB,主存块大小为 32B。现有 C 语言程序段如下:
for (i = 0; i < 24; i++)
for (j = 0; j < 64; j++) a[i][j] = 10;
已知二维数组 a 按行优先存放,在虚拟地址空间中分配的起始地址为 0042 2000H,sizeof(int)=4,假定在 M 上执行上述程序段之前数组 a 不在主存,且在该程序段执行过程中不会发生页面置换。请回答下列问题。
(1) 数组 a 分为几个页面存储?对于数组 a 的访问,会发生几次缺页异常?页故障地址各是什么?
(2) 不考虑变量 i 和 j,该程序段的数据访问是否具有时间局部性?为什么?
(3) 计算机 M 的虚拟地址(A31~A0)中哪几位用作块内地址?哪几位用作 Cache 组号?a[1][0] 的虚拟地址是多少?其所在主存块对应的 Cache 组号是多少?
(4) 数组 a 占用多少主存块?假设上述程序段执行过程中数组 a 的访问不会和其他数据发生 Cache 访问冲突,则数组 a 的 Cache 命中率是多少?若将循环中 i 和 j 的次序按如下方式调换:
for (j = 0; j < 64; j++)
for (i = 0; i < 24; i++) a[i][j] = 10;
则数组 a 的 Cache 命中率又是多少?
44
上题中 C 程序段在计算机 M 上的部分机器级代码如下,每个机器级代码行中依次包含指令序号、虚拟地址、机器指令和汇编指令。
for (i = 0; i < 24; i++)
1 00401072 C7 45 F8 00 00 00 00 mov[ebp-8], 0
2 00401079 EB 09 jmp 00401084h
3 0040107B 8B 55 F8 mov eax, [ebp-8]
... ... ...
7 00401088 7D 32 jge 004010bch
for (j = 0; j < 64; j++)
8 0040108A C7 45 FC 00 00 00 00 mov[ebp-4], 0
... ... ...
a[i][j] = 10;
... ... ...
19 004010AE C7 84 82 00 20 42 00 0A 00 00 00 mov[ecx+edx*4+00422000h], 0Ah
20 ... ...
请回答下列问题。
(1) 第 20 条指令的虚拟地址是多少?
(2) 已知第 2 条 jmp 和第 7 条 jge 都是跳转指令,其操作码分别是 EBH 和 7DH,跳转地址分别为 0040 1084H、0040 10BCH,这两条指令都采用什么寻址方式?给出第 2 条指令 jmp 的跳转目标地址计算过程。
(3) 已知第 19 条 mov 指令的功能是“a[i][j]←10”,其中 ecx 和 edx 为寄存器名,0042 2000H 是数组 a 的首地址,指令中源操作数采用什么寻址方式?已知 edx 中存放的是变量 j,ecx 中存放的是什么?根据该指令的机器码判断计算机 M 采用的是大端还是小端方式。
(4) 第一次执行第 19 条指令时,取指令过程中是否会发生缺页异常?为什么?
操作系统
45
现要求学生使用 swap 指令和布尔型变量 lock 实现临界区互斥。lock 为线程间共享的变量。lock 的值为 TRUE 时线程不能进入临界区,为 FALSE 时线程能够进入临界区。某同学编写的实现临界区互斥的伪代码如题 45(a) 图所示。
(1) 题 45(a) 图中伪代码中哪些语句存在错误?将其改为正确的语句(不增加语句条数)。
(2) 题 45(b) 图中给出了两个变量值的函数 newSwap() 的代码是否可以用函数调用语句“newSwap(&key, &lock)”代替指令“swap key, lock”以实现临界区的互斥?为什么?
46
进程 P 通过执行系统调用从键盘接收一个字符的输入,已知此过程中与进程 P 相关的操作包括:①将进程 P 插入就绪队列;②将进程 P 插入阻塞队列;③将字符从键盘控制器读入系统缓冲区;④启动键盘中断处理程序;⑤进程 P 从系统调用返回;⑥用户在键盘上输入字符。以上编号①~⑥仅用于标记操作,与操作的先后顺序无关。请回答下列问题。
(1) 按照正确的操作顺序,操作①的前一个和后一个操作分别是上述操作中的哪一个?操作⑥的后一个操作上述操作中的哪一个?
(2) 在上述哪个操作之后 CPU 一定从进程 P 切换到其他进程?在上述哪个操作之后 CPU 调度程序才能选择进程 P 执行?
(3) 完成上述哪个操作的代码属于键盘驱动程序?
(4) 键盘中断处理程序执行时,进程 P 处于什么状态?CPU 处于内核态还是用户态?
计算机网络
47
如图,主机 H 登录到 FTP 服务器后,向服务器上传一个大小为 18000B 的文件 F,假设 H 传输 F 建立数据链接时,选择的初始序号为 100,MSS=1000B,拥塞控制的初始阈值是 4MSS,RTT=10ms,忽略 TCP 的传输时延,在 F 的传送过程中,H 以 MSS 段向服务器发送数据,且始终没有错误,丢包和乱序。
(1) FTP 的控制连接是持久的还是非持久的?FTP 的数据连接是持久的还是非持久的?H 登录服务器时,建立的 FTP 连接是数据连接还是控制连接。
(2) H 通过数据连接发送 F 时,F 的第一个字节序号是多少?在断开数据连接的过程中,FTP 发送的第二次挥手的 ACK 序号是?
(3) F 发送过程中,当 H 收到确认序号为 2101 的确认时,H 的拥塞调整为多少?收到确认序号为 7101 的确认段时,H 的拥窗口调整为多少
(4) H 从请求建立数据连接开始,到确认 F 已被服务全部接收为止,至少要多长时间?期间应用层数平均发送速率是多少?