学习思维导图:
# 栈、队列和数组
## 栈和队列基本概念
## 栈和队列的顺序存储结构
## 栈和队列的链式存储结构
## 多维数组的存储
## 特殊矩阵的压缩矩阵
## 栈、队列和数据的应用
学习思维导图:
# 栈、队列和数组
## 栈和队列基本概念
## 栈和队列的顺序存储结构
## 栈和队列的链式存储结构
## 多维数组的存储
## 特殊矩阵的压缩矩阵
## 栈、队列和数据的应用
栈 是一个元素的集合,加入元素的操作叫做 “压栈”(push),而移除元素的操作叫做 “出栈”(pop)。它遵循 后进先出(LIFO, Last In First Out) 的原则。这意味着最后被压入栈的元素是第一个被弹出的元素。
push(element): 将元素添加到 栈 的顶部。pop(): 移除并返回 栈顶 的元素。如果 栈 为空,这个操作可能会抛出一个错误或返回特定的值(例如 null 或 undefined),具体取决于实现。peek() 或 top(): 返回 栈顶 的元素但不移除它。这只是一个查看操作,栈 的内容不会改变。如果 栈 为空,这个操作可能会抛出一个错误或返回特定的值。isEmpty(): 判断 栈 是否为空。如果 栈 为空,返回 true;否则返回 false。size() 或 length(): 返回 栈 中元素的数量。栈 的实现方式有两种,顺序栈 和 链式栈。
顺序栈 是在 顺序表 的基础上实现 栈结构,
链式栈 是在 链表 的基础上实现 栈结构。
顺序栈是使用 数组 来实现的 栈,利用数组的索引来模拟 栈 的操作。
与普通的线性表不同,栈 的操作被限制在表的一端进行,这一端被称为 栈顶 (Top),另一端被称为 栈底 (Bottom)。
顺序栈的关键在于 栈顶指针,栈顶指针是一个整数变量,用于指示 栈顶 元素在 数组 中的位置。其值的变化直接反映了栈中元素的变化。
当 栈空 时,一般将 栈顶指针设置为 1,当 栈满 时,栈顶指针指向 数组 中的最后一个元素。
当元素 入栈 时,将栈顶指针 向后 移动一个位置、然后放置新元素即可。当元素 出栈 时,需要将栈顶指针 向前 移动一个位置。
当然,入栈需要保证栈不满,出栈需要保证栈不空。
#define MAX_SIZE 100 // 定义栈的最大容量
// 定义顺序栈的结构
typedef struct {
int data[MAX_SIZE]; // 使用数组存储数据
int top; // 栈顶指针
} SeqStack;// 初始化栈
SeqStack* initStack() {
SeqStack* stack = (SeqStack*)malloc(sizeof(SeqStack));
if(!stack) {
printf("Failed to allocate memory for stack\n");
exit(1);
}
// 栈顶指针初始化为 -1,表示栈为空
stack->top = -1;
return stack;
}// 入栈操作
bool push(SeqStack* stack, int value) {
if (isFull(stack)) {
printf("Stack is full!\n");
return false;
}
// 先移动栈顶指针,再存放元素
stack->data[++stack->top] = value;
return true;
}// 出栈操作
bool pop(SeqStack* stack, int* value) {
if (isEmpty(stack)) {
printf("Stack is empty!\n");
return false;
}
// 先取出元素,再移动栈顶指针
*value = stack->data[stack->top--];
return true;
}// 获取栈顶元素
bool peek(SeqStack* stack, int* value) {
if (isEmpty(stack)) {
printf("Stack is empty!\n");
return false;
}
*value = stack->data[stack->top];
return true;
}// 判断栈是否为空
// 当栈中没有元素时,栈顶指针通常指向一个特殊的位置,例如 -1。
bool isEmpty(SeqStack* stack) {
return stack->top == -1;
}
// 判断栈是否已满
// 当栈顶指针指向数组中的最后一个元素时,说明栈已经满了
bool isFull(SeqStack* stack) {
return stack->top == MAX_SIZE - 1;
}栈的 链式存储结构 利用 单链表 来实现栈的功能。

在 链式栈 实现中,一般 头结点不存放数据,仅作为链表的固定起点。栈顶元素始终为 head->next。这样依然可以保证 入栈 和 出栈 的时间复杂度为 $O(1)$。
链式栈具备以下 重要特性:
head 始终存在,不存储实际数据,只作为哨兵节点。head->next。head->next == NULL。head->next 前插入新节点;出栈时删除 head->next。// 定义链式栈的节点结构
typedef struct Node {
int data;
struct Node* next;
} Node;
// 定义链式栈(带头结点)
typedef struct {
Node* head; // 指向头结点
} LinkedStack;// 初始化栈(带头结点)
LinkedStack* initStack() {
LinkedStack* stack = (LinkedStack*)malloc(sizeof(LinkedStack));
if (!stack) {
printf("Failed to allocate memory for stack\n");
exit(1);
}
stack->head = (Node*)malloc(sizeof(Node)); // 创建头结点
if (!stack->head) {
printf("Failed to allocate memory for head node\n");
exit(1);
}
stack->head->next = NULL; // 初始为空栈
return stack;
}// 入栈操作(头插法)
void push(LinkedStack* stack, int value) {
Node* newNode = (Node*)malloc(sizeof(Node));
if (!newNode) {
printf("Failed to allocate memory for new node\n");
exit(1);
}
newNode->data = value;
newNode->next = stack->head->next;
stack->head->next = newNode;
}// 出栈操作
bool pop(LinkedStack* stack, int* value) {
if (isEmpty(stack)) {
printf("Stack is empty!\n");
return false;
}
Node* topNode = stack->head->next;
*value = topNode->data;
stack->head->next = topNode->next;
free(topNode);
return true;
}// 获取栈顶元素
bool peek(LinkedStack* stack, int* value) {
if (isEmpty(stack)) {
printf("Stack is empty!\n");
return false;
}
*value = stack->head->next->data;
return true;
}// 判断栈是否为空
bool isEmpty(LinkedStack* stack) {
return stack->head->next == NULL;
}队列是一种遵循 先入先出 (FIFO, First In First Out) 原则的线性数据结构。元素在 队尾 添加,在 队首 删除。
enqueue(element): 将元素添加到 队列 的尾部。dequeue(): 从 队列 的头部移除并返回元素。如果 队列 为空,此操作可能会返回特定的值或引发错误。front() 或 peek(): 返回 队首 的元素但不移除它。isEmpty(): 判断 队列 是否为空。size(): 返回 队列 中元素的数量。顺序队列通常是指使用固定大小的数组来存储 队列 中的元素。在顺序队列中,通常有两个指标:一个是 队头(front),另一个是 队尾(rear)。当插入(入队)或删除(出队)元素时,这两个指标会移动。
顺序队列有一个明显的问题:随着时间的推移,队列 中的元素可能向数组的末尾移动,即使 队列 并不满,也可能无法再插入新的元素,因为 队尾 已经达到了数组的末尾。这种现象称为 假溢出。
为了解决上述问题,可以使用 循环队列(也称为环形队列)。循环队列 是顺序队列的一个变种,它把数组视为一个循环的结构。当 队尾 指标达到数组的最后一个位置并且还需要进一步移动时,它会回到数组的起始位置。
需要注意的是,在 循环队列 中需要牺牲一个存储单元以区分 队空 和 队满 的情况。
front == rear 时,队列为空(rear + 1) % size == front 时,队列为满#define MAX_SIZE 100
typedef struct {
int data[MAX_SIZE];
int front, rear;
} CircularQueue;
// 初始化队列
void initQueue(CircularQueue* q) {
q->front = q->rear = 0;
}// 入队操作
bool enqueue(CircularQueue* q, int value) {
if (isFull(q)) return false;
q->data[q->rear] = value;
q->rear = (q->rear + 1) % MAX_SIZE;
return true;
}// 出队操作
bool dequeue(CircularQueue* q, int* value) {
if (isEmpty(q)) return false;
*value = q->data[q->front];
q->front = (q->front + 1) % MAX_SIZE;
return true;
}// 获取队首元素
bool front(CircularQueue* q, int* value) {
if (isEmpty(q)) return false;
*value = q->data[q->front];
return true;
}
// 获取队尾元素
bool rear(CircularQueue* q, int* value) {
if (isEmpty(q)) return false;
*value = q->data[(q->rear - 1 + MAX_SIZE) % MAX_SIZE];
return true;
}// 判断队列是否为空
bool isEmpty(CircularQueue* q) {
return q->front == q->rear;
}
// 判断队列是否满
bool isFull(CircularQueue* q) {
return (q->rear + 1) % MAX_SIZE == q->front;
}链式队列 是使用 链表结构 来实现的 队列。它充分利用了链表的动态性质,允许队列在运行时 动态增长或缩小,不存在顺序存储中需要预先分配空间的问题。
链式队列通常包含三个指针:
front 不直接指向第一个有效结点,而是 指向头结点。front->next。rear == front == head。链式队列一般使用 单链表 来实现,入队和出队操作可以基于队头和队尾指针实现:
O(1) 时间。O(1) 时间。这比用数组实现的队列在需要移动元素时效率更高。
// 结点定义
typedef struct QNode {
int data; // 数据域
struct QNode *next; // 指针域
} QNode;
// 链式队列结构
typedef struct {
QNode *front; // 队头指针 (指向头结点)
QNode *rear; // 队尾指针 (指向队尾结点)
} LinkQueue;
// 初始化队列(带头结点)
void InitQueue(LinkQueue *Q) {
QNode *head = (QNode *)malloc(sizeof(QNode)); // 申请头结点
head->next = NULL;
Q->front = Q->rear = head; // front、rear 都指向头结点
}// 入队操作
void EnQueue(LinkQueue *Q, int x) {
QNode *node = (QNode *)malloc(sizeof(QNode));
node->data = x;
node->next = NULL;
Q->rear->next = node; // 新结点挂在队尾
Q->rear = node; // 更新队尾指针
}// 出队操作
int DeQueue(LinkQueue *Q, int *x) {
if (IsEmpty()) return 0; // 队空
QNode *p = Q->front->next; // 队头第一个有效结点
*x = p->data;
Q->front->next = p->next; // 删除结点
if (Q->rear == p) { // 如果队尾被删空了
Q->rear = Q->front; // rear 重新指向头结点
}
free(p);
return 1;
}// 判断队列是否为空
int IsEmpty(LinkQueue Q) {
return Q.front == Q.rear;
}二叉表达式树 是一种特殊的二叉树,用于表示算术或逻辑表达式。它的每个 叶子节点 通常存放 操作数(operand,如数字或变量),每个 非叶子节点 存放 操作符(operator,如 +, -, *, /)。
前序表达式(Preorder,波兰表示法)、中序表达式(Infix)和后序表达式(Postorder,逆波兰表示法)是根据二叉表达式树的不同遍历方式得到的表达式结果。具体来说:
这三种表达式的 操作符 和 操作数 间的相对位置有所不同:
| 表达式类型 | 描述 | 示例表达式 | 对应的公式 |
|---|---|---|---|
| 前序 | 操作符位于其操作数之前 | * + A B C | (A + B) * C |
| 中序 | 操作符位于其两个操作数之间,最常见的表示法 | (A + B) * C | (A + B) * C |
| 后序 | 操作符位于其操作数之后 | A B + C * | (A + B) * C |
中序表达式求值涉及到两个主要的数据结构:操作符栈 与 操作数栈。其核心思路是逐个读取中序表达式的字符,根据字符的类型(操作数、操作符、括号)进行不同的处理,最终得到表达式的值。
+、-、*、/等):中序表达式求值的过程可以参照以下流程图进行理解:
以表达式 3 + (5 * 2 - 8) 说明计算过程:
| 步骤 | 输入字符 | 操作 | 操作符栈 | 数据栈 |
|---|---|---|---|---|
| 1 | 3 | 压入数据栈 | 3 | |
| 2 | + | 压入 操作符栈 | + | 3 |
| 3 | ( | 压入 操作符栈 | +, ( | 3 |
| 4 | 5 | 压入数据栈 | +, ( | 3, 5 |
| 5 | * | 压入 操作符栈 | +, (, * | 3, 5 |
| 6 | 2 | 压入数据栈 | +, (, * | 3, 5, 2 |
| 7 | - | * 优先级 高于 -,* 出栈计算后,将 - 入栈 | +, (, - | 3, 10 |
| 8 | 8 | 压入数据栈 | +, (, - | 3, 10, 8 |
| 9 | ) | 处理到 ( 之前的所有操作符 | + | 3, 2 |
| 10 | 用 + 运算符计算 | 5 |
后序表达式求值主要依赖一个 操作数栈。其核心思路是逐个读取后序表达式的元素,并根据元素的类型(操作数或操作符)进行处理。
后序表达式求值的过程可以参照以下流程图进行理解:
flowchart TD
A[开始: 初始化操作数栈] --> B[读取后序表达式的下一个元素]
B --> C{是否还有元素?}
C -->|否| H[栈顶元素即为最终结果]
H --> I[结束]
C -->|是| D{当前元素类型?}
D -->|操作数| E[将操作数压入栈中]
E --> B
D -->|操作符| F[从栈中弹出两个操作数<br/>注意: 先弹出的是第二操作数<br/>后弹出的是第一操作数]
F --> G[执行运算并将结果压入栈中]
G --> B
style A fill:#e1f5fe
style I fill:#c8e6c9
style D fill:#fff3e0
style E fill:#f3e5f5
style F fill:#ffebee
style G fill:#ffebee
style H fill:#e8f5e8以表达式 3 5 2 * 8 - + 说明计算过程:
| 步骤 | 输入字符 | 操作 | 操作数栈 |
|---|---|---|---|
| 1 | 3 | 压入 操作数栈 | 3 |
| 2 | 5 | 压入 操作数栈 | 3, 5 |
| 3 | 2 | 压入 操作数栈 | 3, 5, 2 |
| 4 | * | 弹出两个操作数并相乘,结果压入 操作数栈 | 3, 10 |
| 5 | 8 | 压入 操作数栈 | 3, 10, 8 |
| 6 | - | 弹出两个操作数并相减,结果压入 操作数栈 | 3, 2 |
| 7 | + | 弹出两个操作数并相加,结果压入 操作数栈 | 5 |
将中缀表达式转换为后缀表达式的算法思想如下:
初始化一个 操作符栈,从左向右开始扫描中缀表达式;
(,入栈;),则依次把栈中的运算符加入后缀表达式中,直到出现 (,从栈中删除 (;( 以外的栈顶运算符时,直接入栈;中序转后序的过程可以参照以下流程图进行理解:
flowchart TD
A[开始:初始化操作符栈] --> B[从左向右扫描中缀表达式]
B --> C{读取下一个字符}
C -->|数字| D[直接添加到后缀表达式]
C -->|左括号| E[直接入栈]
C -->|右括号| F[弹出栈中运算符到后缀表达式]
C -->|运算符| G{当前运算符优先级 > 栈顶运算符优先级?}
D --> H{是否扫描完成?}
E --> H
F --> I{栈顶是否为左括号?}
I -->|否| F
I -->|是| J[弹出左括号但不加入后缀表达式]
J --> H
G -->|是| K[直接入栈]
G -->|否| L[弹出栈顶运算符到后缀表达式]
L --> M{栈空或栈顶为左括号或优先级更低?}
M -->|否| L
M -->|是| N[当前运算符入栈]
K --> H
N --> H
H -->|否| C
H -->|是| O[弹出栈中所有剩余运算符]
O --> P[结束:得到后缀表达式]
style A fill:#e1f5fe,font-size:24px
style P fill:#c8e6c9,font-size:24px
style D fill:#fff3e0,font-size:24px
style E fill:#fce4ec,font-size:24px
style F fill:#fce4ec,font-size:24px
style G fill:#f3e5f5,font-size:24px
classDef default font-size:18px
classDef largeText font-size:24px
class A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P largeText
linkStyle default font-size:22px以中序表达式 a/b+(c*d-e*f)/g 为例,可以通过如下步骤将其转换为后续表达式:
| 待处理序列 | 栈 | 后缀表达式 | 当前扫描元素 | 动作 |
|---|---|---|---|---|
a/b+(c*d-e*f)/g | a | a 加入后缀表达式 | ||
/b+(c*d-e*t)/g | a | / | / 入栈 | |
b+(c*d-e*f)/g | / | a | b | b 加入后缀表达式 |
+(c*d-e*f)/g | / | ab | + | + 优先级 低于栈顶的 /,弹出 / |
+(c*d-e*f)/g | ab/ | + | + 入栈 | |
(c*d-e*f)/g | + | ab/ | ( | ( 入栈 |
c*d-e*f)/g | +( | ab/ | c | c 加入后缀表达式 |
*d-e*f)/g | +( | ab/c | * | 栈顶为 (,* 入栈 |
d-e*t)/g | +(* | ab/c | d | d 加入后缀表达式 |
-e*f)/g | +(* | ab/cd | - | - 先级低于栈顶的 *,弹出 * |
-e*f)/g | +( | ab/cd* | - | 栈顶为 (,- 入栈 |
e*t)/g | +(- | ab/cd* | e | e 加入后缀表达式 |
*f)/g | +(- | ab/cd*e | * | * 优先级 高于栈顶的 -, * 入栈 |
f)/g | +(-* | ab/cd*e | f | f 加入后缀表达式 |
)/g | +(-* | ab/cd*ef | ) | 把栈中 ( 之前的符号加入表达式 |
/g | + | ab/cd*ef*- | / | / 优先级 高于栈顶的 +,/ 入栈 |
g | +/ | ab/cd*ef*- | g | g 加入后缀表达式 |
+/ | ab/cd*ef*-g | 扫描完毕,运算符依次退栈加入表达式 | ||
ab/cd*ef*-g/+ | 完成 |
入栈出栈是常考的问题,这类问题的核心可以被总结为以下两种范式:
这里给出这两个常见问题的解答。
给定一个入栈序列,其出栈序列可能有很多种,因为一个元素的出栈时间比较灵活,比如它可以一入栈马上出栈,也可以等一会再出栈。要辨别不可能的出栈系列,需要 抓住关键规则:只有 栈顶元素 能够最先出栈。
也就是说,对于下图这种情况,A 被 B 压住了,在出栈序列中,A 一定在 B 的后面。如果某个出栈序列中 A 在 B 的前面,则这种出栈序列是不可能出现的。
考虑这样一个问题:有 $n$ 个不同的元素(例如 $1,2,\cdots,n$),我们按照某种顺序依次将它们 入栈,并且在任意时刻可以选择 出栈。每个元素都必须恰好入栈一次、出栈一次。我们想知道,所有可能的出栈序列共有多少种。
这个问题的答案可以用 卡特兰数(Catalan number) 来表示。卡特兰数的公式如下:
$$ C_n = \frac{1}{n+1}\binom{2n}{n} $$
也就是说,上述问题中 $n$ 个元素的所有可能出栈序列数量就是 $C_n$。
那么为什么入栈出栈序列总数可以用卡特兰数来表示呢?
我们可以把每一次操作用数字表示:
+1-1整个过程总共有 $2n$ 次操作,其中有 $n$ 次入栈,$n$ 次出栈。为了保证操作合法(不能在栈为空时出栈),必须满足:在任意时刻,出栈次数 不能超过 入栈次数。
这恰好 与卡特兰数的经典定义相对应:卡特兰数计数的就是符合类似限制的序列数量。因此,入栈出栈序列数量正好是 $C_n$。
卡特兰数不仅出现在入栈出栈序列中,还常 出现在很多等价问题中,例如:
二叉树计数 给定 $n$ 个不同节点,可以构造的不同形态二叉树的数量为 $C_n$。
括号匹配 $n$ 对括号的合法匹配序列数量也为 $C_n$。 例如,当 $n=2$ 时,合法的序列有:
()() (())
在计算机内存中,数组元素是 连续存放 的。对于一个二维数组来说,它实际上只是对一维数组的一种逻辑抽象。理解其存储方式的关键在于:如何将二维坐标 $(i, j)$ 映射到一维的线性内存地址。

假设:
那么数组中元素 $a[i][j]$ 的存储地址为:
$$ \text{Addr}(a[i][j]) = A + (i \times C + j) \times B $$
其中:
举个 C 语言的示例进行说明,如果我们定义一个二维数组:
int a[2][3] = {{1, 2, 3}, {4, 5, 6}};
这个数组的内存布局可以视为一个一维数组,如下所示:
+---------+---------+---------+---------+---------+---------+
| a[0][0] | a[0][1] | a[0][2] | a[1][0] | a[1][1] | a[1][2] |
+---------+---------+---------+---------+---------+---------+
0x100 0x104 0x108 0x10C 0x110 0x114
需要注意的是,不同语言对多维数组的存储顺序可能不同:
如果按列主序存储,上面例子 a[2][3] 的内存布局会变为:
+---------+---------+---------+---------+---------+---------+
| a[0][0] | a[1][0] | a[0][1] | a[1][1] | a[0][2] | a[1][2] |
+---------+---------+---------+---------+---------+---------+
什么是 对称矩阵:对于矩阵$A$中的任意一个元素$a_{i, j}$都有 $a_{i, j} = a_{j ,i}$,
所以为了 节省存储空间,可以使用一位数组$B$进行存储
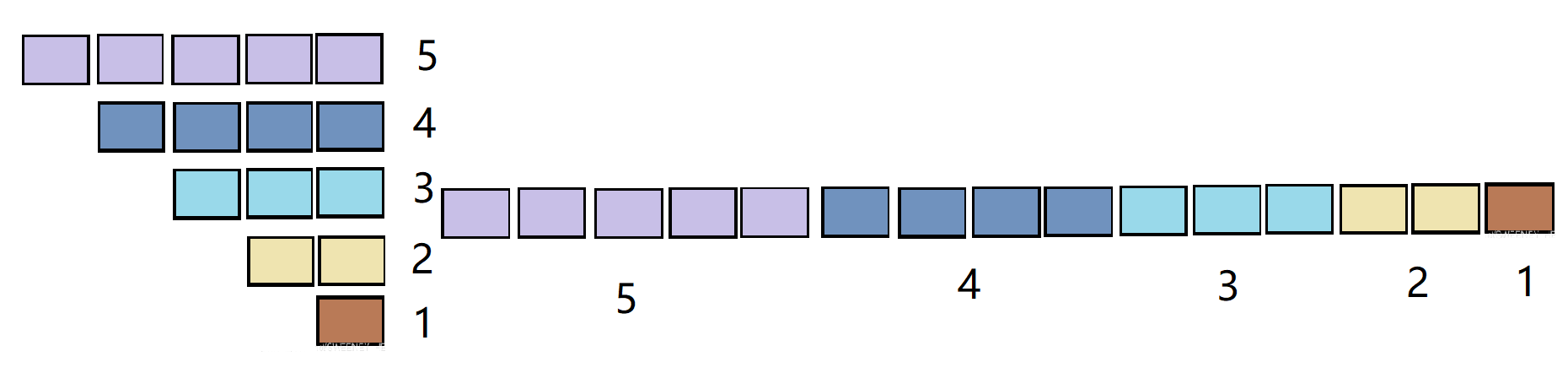
如何计算对称矩阵中元素的下标
$A$ 中的元素 $a_{i, j}$ 在数组 $B$ 的下标
$$k = 1 + 2 + \cdots + (i-1) + j - 1 = i(i-1)/2+j-1$$
元素为
以上三角矩阵 $A$ 为例,上半部分元素首先按序存储在一位数组 $B$ 中,在最后一个位置添加一个元素,用于存储下三角位置对应的元素
$A$ 中的元素 $a_{i, j}$ 在数组 $B$ 的下标
$$k = n + (n+1) _ \cdots + (n-i+2) + (j-i+1) - 1 = (i-1)(2n-i+2)/2 + (j-i)$$
元素为
稀疏矩阵(Sparse Matrix)是指在矩阵中大部分元素为零的矩阵。与之相对的是 稠密矩阵(Dense Matrix),即大部分元素非零。
$$ A_{6 \times 7} = \begin{bmatrix} 0 & 0 & 1 & 0 & 0 & 0 & 0 \\ 0 & 2 & 0 & 0 & 0 & 0 & 0 \\ 3 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 5 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 6 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 7 & 4 \end{bmatrix} $$
由于 稀疏矩阵 的非零元素远少于零元素,存储整个矩阵(包括所有零元素)会浪费大量空间。因此,稀疏矩阵通常使用特定的数据结构(三元组表 和 十字链表)来高效存储和操作,只保存非零元素及其位置信息。
三元组表(Triple Table) 是一种稀疏矩阵的顺序存储方法。它利用三个一维数组(或一个结构体数组)分别存放非零元素的 行号、列号 和 数值,从而节省内存空间。
对于一个 $m \times n$ 的稀疏矩阵 $A$,若其中只有 $t$ 个非零元素,则三元组表的长度就是 $t$。存储时,一般约定按照 行序优先(先按行号从小到大排序,行号相同时再按列号从小到大)存放,便于后续矩阵运算和查找。

在程序实现时,常见的两种方式是:
row[]、col[] 和 val[] 分别保存行号、列号和数值。Triple,包含 (row, col, value) 三个字段,再用一个一维数组 Triple data[t] 来存储。#define MAXSIZE 100 // 最大非零元素个数
// 稀疏矩阵三元组表(分开存储)
typedef struct {
int m, n, t; // 矩阵的行数、列数、非零元素个数
int row[MAXSIZE]; // 行号数组
int col[MAXSIZE]; // 列号数组
int val[MAXSIZE]; // 数值数组
} TSMatrix;#define MAXSIZE 100 // 最大非零元素个数
// 三元组
typedef struct {
int row, col; // 行号、列号
int val; // 数值
} Triple;
// 稀疏矩阵三元组表(结构体存储)
typedef struct {
int m, n, t; // 矩阵的行数、列数、非零元素个数
Triple data[MAXSIZE]; // 非零元素数组
} TSMatrix;三元组表的优点是 存储结构简单、节省空间,但缺点是 随机访问代价较高 —— 若要访问某个元素,需要顺序扫描查找对应行列下标,适合用于矩阵转置、稀疏矩阵相加、输出等操作。
在实际应用中,如果需要频繁地进行按行、按列的运算,就会引入 十字链表 等更复杂的存储方式。
十字链表(Cross List) 是一种用于稀疏矩阵的存储结构,它的核心思想是利用行方向和列方向两个链表同时组织非零元素,从而使得既能按行遍历,也能按列遍历,访问效率都较高。相比于普通的顺序存储或单一链表结构,十字链表在需要频繁进行矩阵运算、转置或按行按列混合访问的场景下具有明显优势。
下图给出了一个十字链表的实例:
在十字链表中,每一个非零元素都会建立一个结点。该结点需要记录行号(i)、列号(j)、元素值(value),同时还要保存两个方向的指针:right 指针指向同一行中的下一个非零元素,down 指针指向同一列中的下一个非零元素。借助这两个指针,矩阵可以在行链和列链之间灵活切换,实现双向高效的访问。
为了快速定位某一行或某一列的首个非零元素,还需要额外设置行头指针数组(rhead)和列头指针数组(chead)。每一行和每一列都对应一个头指针,这些头指针并不存储具体数值,而是起到索引的作用,使得从某一行或某一列开始的遍历可以在常数时间内定位到第一个非零元素。
// 十字链表结点定义
typedef struct CrossListNode {
int row; // 行号
int col; // 列号
int value; // 元素值
struct CrossListNode* right; // 指向同一行下一个非零元素
struct CrossListNode* down; // 指向同一列下一个非零元素
} CrossListNode;// 十字链表结构
typedef struct {
CrossListNode** rhead; // 行头指针数组
CrossListNode** chead; // 列头指针数组
int rows; // 矩阵行数
int cols; // 矩阵列数
int nums; // 非零元素个数
} CrossList;十字链表的优势主要体现在三个方面:其一,空间效率高,仅存储非零元素及必要的指针;其二,支持按行或按列的双向遍历,在算法实现中非常灵活;其三,插入与删除操作方便,只需在相应行和列的链表中调整指针即可,而不必像顺序存储那样整体移动元素。因此,十字链表常被用于稀疏矩阵运算和图的邻接矩阵存储,是数据结构与图论中重要的一种存储方式。
三对角矩阵是一种特殊的稀疏矩阵,它除了主对角线外,只在其上下相邻的两条对角线上有非零元素,其余元素均为零。
由于仅有三条对角线是非零的,我们可以只存储这三条线来 节省空间(从 $n^2$ 降为 $3n-2$ 个数字)。
一种常用存储方式是使用三个长度为 n 的数组:
a[2...n]:下对角线(从第 2 行开始有值)b[1...n]:主对角线c[1...n-1]:上对角线(到第 n-1 行)