这是本节的多页打印视图。
点击此处打印 .
返回本页常规视图 .
计算机网络
计算机网络在 408 试卷中占据 25 分,是分数占比最小的一门科目,包含 8 道选择题以及 1 道大题。但是复习难度其实并不小,因为知识点庞杂且琐碎,记忆性内容较多,理解性内容较少,并且在选择题中常常考察冷门知识点,所以想在 25 分中得到 20 分以上其实并不容易。
建议大家在复习计算机网络时要抓住主干知识,确保大题和基本的选择题题型可以准确无误地做出来。对于一些冷门知识点,可以选择性放弃,只保留一个基本的印象即可,不需要深入理解,如果真地考察到,可以根据自己的印象大致蒙一个答案。
计算机网络的考察目标包含如下内容(来自 408 考研大纲):
掌握计算机网络的基本概念、基本原理和基本方法。 掌握典型计算机网络的结构、协议、应用以及典型网络设备的工作原理。 能够运用计算机网络的基本概念、基本原理和基本方法进行网络系统的分析、设计和应用。 1 - 计算机网络体系结构 可能在选择题中考察,需要掌握 TCP/IO 模型和 ISO/OSI 模型的不同,并且能够从一个宏观的角度看待网络不同层次之间的联系。
学习思维导图:
# 计算机网络概述
## 基本概念
- 定义、组成和功能
- 分类
- 主要性能指标
## 体系结构
- 分层结构
- 网络协议、接口、服务等概念
- ISO/OSI参考模型和TCP/IP模型
1.1 - 分层结构 掌握 ISO/OSI 模型和 TCP/IP 的每一层功能,以及两个模型的对应关系,可能在选择题中考察。
ISO/OSI 模型 OSI 参考模型有 7 层,自下而上依次为【物理层、数据链路层、网络层、传输层、会话层、表示层、应用层】(记忆:物链网输会示用)。低三层统称为 通信子网 ,它是为了联网而附加的通信设备,完成数据的传输功能;高三层统称为 资源子网 ,它相当于计算机系统,完成数据的处理等功能。传输层承上启下。
OSI 参考模型的层次结构如下图所示:
物理层 物理层的传输单位是比特,功能是在物理媒体上为数据端设备透明地传输原始比特流,不用参与数据封装工作。
为了实现该功能,物理层需要定义硬件设备标准,如电缆类型、接口类型、电压标准等。
数据链路层 数据链路层的传输单位是帧,两台主机之间的数据传输总是在一段一段的链路上传送的,这就需要使用专门的链路层协议。
数据链路层将网络层交来的 IP 分组封装成帧,并且可靠地传输到相邻结点的网络层。主要作用是加强物理层传输原始比特流的功能,将物理层提供的可能出错的物理连接改造为尽可能可靠的数据链路。数据链路层的功能可以概括为:物理寻址、组帧、差错控制、点对点流量控制、数据重发和传输管理等。
网络层 网络层(Netweork Layer)的传输单位是数据报,它关心的是通信子网的运行控制,主要任务是把网络层的协议数据单元(分组)从源端传到目的端,为分组交换网上的不同主机提供通信服务。关键问题是对分组进行路由选择,并实现整个网络的流量控制。
传输层 传输层(Transport Layer)的传输单位是报文段或用户数据报,传输层负责主机中两个进程之间的通信,功能是为端到端连接提供可靠的传输服务,为端到端连接提供流量控制(端到端)、差错控制、服务质量、数据传输管理等服务。
数据链路层提供的是点到点的通信,传输层提供的是端到端的通信,两者不同。点到点可以理解为主机到主机之间的通信;端到端的通信是指运行在不同主机内的两个进程之间的通信,只有传输层及以上各层的通信才能称为端到端。
会话层 会话层(Session Layer)允许不同主机上的各个进程之间进行会话。这种服务主要为用户进程建立连接,并在连接上有序地传输数据,这就是会话。
会话层负责管理主机间的会话进程,包括建立、管理及终止进程间的会话。会话层包含一种称为检查点的机制来维持可靠会话,使通信会话在通信失效时从检查点继续恢复通信,即断点下载的原理。
表示层 表示层主要处理在两个通信系统中交换信息的表示方式。
不同机器采用的编码和表示方法不同,使用的数据结构也不同。
为了使不同表示方法的数据和信息之间能互相交换,表示层采用抽象的标准方法定义数据结构,并采用标准的编码形式。此外,数据压缩、加密和解密 也是表示层的功能。
应用层 应用层是 OSI 参考模型的最高层,是用户与网络的接口。应用层为特定类型的网络应用提供访问 OSI 参考模型环境的手段。因为用户的实际应用多种多样,这就要求应用层采用不同的应用协议来解决不同类型的应用要求,因此应用层是最复杂的一层,使用的协议也最多
TCP/IP 模型 TCP/IP 模型从低到高依次为【网络接口层(对应 OSI 参考模型中的物理层和数据链路层)、网际层、传输层和应用层(对应 OSI 参考模型中的会话层、表示层和应用层)】。TCP/IP 由于得到广泛应用而成为事实上的国际标准。TCP/IP 模型的层次结构如下图所示:
TCP/IP 模型与 OSI 模型的不同点在于 网络接口层 和 应用层,可以理解为 TCP/IP 模型中这两层涵盖了 OSI 协议中多层的功能:
应用层 (各种应用层协议
比如 TELNET, FTP,
SMTP 等)
应用层 (各种应用层协议
比如 TELNET, FTP,
SMTP 等)
学习计算机网络时,我们往往采取折中的办法,即综合 OSI 参考模型和 TCP/IP 模型的优点,采用一种如下图所示的只有 5 层协议的体系结构,即我们所熟知的【物理层、数据链路层、网络层、传输层和应用层】。
协议数据单元 在网络中,协议数据单元(PDU ,Protocol Data Unit)是指在某一层协议中传输的数据单元。每一层在接收来自上一层的数据时,都会在其头部添加控制信息(称为首部 Header),然后将其当作一个新的 PDU 交给下一层处理。这就是所谓的“封装”过程。
OSI 层级 PDU 名称 7 应用层 Data(数据) 6 表示层 Data(数据) 5 会话层 Data(数据) 4 传输层 UDP Datagram(UDP 数据报) 3 网络层 IP Packet(IP 分组,IP 数据包,IP 报文) 2 数据链路层 帧(Frame) 1 物理层 比特(Bit)
对于上表,首要的是掌握英文的名词表述,相比中文,这些表述更加统一和精准,中文翻译良莠不齐,常常有多种表述方式,但是表述的都是一个概念,能见词闻义即可。
1.2 - 网络设备总结 掌握不同网络层次设备的功能,以及能否隔离冲突域和广播域,可能在选择题中考察,也会在大题中作为知识点进行考察。
设备 功能描述 设备位于哪一层 隔离冲突域? 隔离广播域? 中继器 放大或再生数字信号 物理层 否 否 集线器 多个设备的连接,广播所有传入的数据 物理层 否 否 网桥 连接并分隔局域网的段落,减少冲突 数据链路层 是 否 交换机 连接多个设备,仅向目标设备转发数据 数据链路层 是 否 路由器 连接不同的网络并路由数据 网络层 是 是
冲突域 :在一个局域网段中,如果两台计算机在同一时间发送数据,则可能会发生数据冲突。冲突域是可能发生数据冲突的网络区域。交换机可以隔离冲突域,因为它仅向目标设备转发数据。
广播域 :在一个局域网内,广播数据包会被所有设备接收。广播域是所有设备都会接收广播包的网络区域。路由器可以隔离广播域,因为它不会转发广播数据包。
1.3 - 各层协议总结 了解各层所包含的网络协议,以及应用层协议使用的端口号、是依赖 UDP 还是 TCP。
应用层协议 协议 端口号 依赖协议 HTTP 80 (HTTP), 443 (HTTPS) TCP FTP 20 (数据传输), 21 (控制) TCP SMTP 25 TCP POP3 110, 995 (安全版) TCP DNS 53 主要 UDP, 部分 TCP DHCP 67 (服务器端), 68 (客户端) UDP
传输层 TCP, UDP
网络层 IP, ICMP
数据链路层 ARP, PPP, HDLC
2 - 物理层 在选择题中考察,掌握相关概念即可。
学习思维导图:
# 物理层
## 通信基础
- 信道、信号、带宽、码元、波特、速率、信源与信宿等基本概念
- 奈奎斯特定理和香农定理
- 编码和调制
- 电路交换、报文交换与分组交换
- 数据报和虚电路
## 传输介质
- 双绞线、同轴电缆、光纤与无线传输介质
- 物理层接口的特性
## 物理层设备
- 中继器
- 集线器
2.1 - 通信概念 需要了解各个通信指标的概念、奈奎斯特定理和香农定理的应用场景(在哪种信道下适用),以及最大比特率的计算公式,可能在选择题中考察。
通信指标 信道 与信道相关的概念有四个,需要能够辨别这几个名词:
信道 (Channel) :是指进行信息传输的媒介或路径。这可能是一个物理的媒介,例如电缆,或者是无线的,如无线电波。信号 (Signal) :是载有信息的物理现象。例如,电信号、光信号或无线电波。信源 (Source) :产生或发送信息的设备或实体。信宿 (Sink or Destination) :是指接收信息的设备或实体。码元 一个码元(symbol)就是一个脉冲信号,一个脉冲信号有可能携带 1bit 数据,也有可能携带 2bit 数据、4bit 数据。
那么怎么实现一个脉冲信号就能携带多个 bit 数据呢?我们可以通过调制技术来实现,比如设置模拟信号中信号的频率、相位、振幅等。
举个例子:把振幅分成四种,低(00)、中(01)、高(10)、很高(11),这样我发一个脉冲信号,它的振幅是低,那就说明发送的是 00(也就是 2bit),它的振幅是中(01),发送的就是 01(也就是 2bit)… 以此类推
波特 波特(Baud)是数据通信中的一个术语,用来表示符号(或码元)传输速率。具体来说,波特率(Baud rate)指的是每秒钟传输的码元(symbol)的数量。
码元和波特率:一个码元可以携带一个或多个比特的信息。波特率是指每秒钟传输多少个这样的码元。例如,如果波特率为 1000 波特,这意味着每秒可以传输 1000 个码元。
波特率与比特率:波特率和比特率的关系取决于每个码元携带的比特数。
一个码元能携带 1bit 数据,那么比特率 = 波特率。 一个码元能携带 2bit 数据,那么比特率 = 2 倍的波特率。 一个码元能携 4bit 数据,那么比特率 = 4 倍的波特率。 速率 速率(Rate)是指连接到计算机网络上的节点在数字信道上传送数据的速率,也称数据传输速率、数据率或比特率,单位为 b/s(比特/秒)或 bit/s(有时也写为 bps )。
当数据率较高时,可用 kb/s(k = $10^3$)、Mb/s(M = $10^6$)或 Gb/s(G = $10^9$)表示。通常把最高数据传输速率称为带宽。
速率可以用两种指标来衡量:
比特率 :每秒传输的比特数量波特率 :每秒传输的波特数量一个码元可以包含多个比特,如果一个码元携带 $n$ 比特的信息量,则波特率 M 对应的比特率为 $Mn$ bit/s
带宽 带宽(Bandwitdh)本来表示通信线路允许通过的信号频带范围,单位是赫兹(Hz)。而在计算机网络中,带宽表示 网络的通信线路所能传送数据的能力,是数字信道所能传送的“最高数据传输速率”的同义语,单位是比特/秒(b/s)。
时延 时延(Delay)指数据(一个报文或分组)从网络(或链路)的一端传送到另一端所需要的总时间,它由 4 个部分构成,分别为:发送时延、传播时延、处理时延和排队时延。
发送时延
发送时延 = 分组长度 (bit) / 发送速率 (bit/s) 传播时延
传播时延 = 信道长度 (m) / 电磁波在信道上的传播速率 (m/s) 需要区分传输时延和传播时延。传输时延是路由器将分组推出所需的时间,是分组长度和链路传输速率的函数。传播时延是一个比特从一台路由器传播至另一台路由器所需的时间,是两台路由器之间距离的函数,而与分组长度或链路传输速率无关。
处理时延:数据在交换结点为存储转发而进行的一些必要的处理所花费的时间。例如,分析分组的首部、从分组中提取数据部分、进行差错检验或查找适当的路由等。
排队时延:分组在进入路由器后要先在输入队列中排队等待处理。路由器确定转发端口后,还要在输出队列中排队等待转发,这就产生了排队时延。
因此,数据在网络中经历的总时延就是以上 4 部分时延之和:总时延=发送时延+传播时延+处理时延+排队时延。
时延带宽积 时延带宽积(Bandwidth-Delay Product,简称 BDP)
指发送端发送的第一个比特即将到达终点时,发送端已经发出了多少个比特,因此又称以比特为单位的链路长度,即
$$\text{时延带宽积}=\text{传播时延} \times \text{信道带宽}$$
如下图所示,考虑一个代表链路的圆柱形管道,其长度表示链路的传播时延,横截面积表示链路带宽,则时延带宽积表示该管道可以容纳的比特数量。
奈奎斯特定理 奈奎斯特定理说明了在 理想低通(没有噪声、带宽有限) 的信道中的数据极限传输速率,当传输速率小于等于该速率时,不会产生码间串扰。
奈奎斯特定理的核心思想是,为了正确地重构一个连续信号,需要以足够高的采样率对该信号进行采样。具体来说,奈奎斯特定理提供了以下关键观点:
最低采样率:奈奎斯特定理规定,为了准确地采样和重构一个连续信号,采样率必须至少是信号中最高频率成分的两倍(或更高)。这就意味着,如果信号的最高频率成分是 f,则采样率应该至少为 2f。 奈奎斯特频率:最高频率成分的一半,也称为奈奎斯特频率,是一个重要的参考点。信号的频率成分高于奈奎斯特频率的部分将无法正确地重构,导致混叠(aliasing)效应,损害信号质量。 混叠效应:如果采样率低于奈奎斯特频率的两倍,那么高于奈奎斯特频率的信号成分将在采样后出现混叠,即被误识别为低于奈奎斯特频率的信号成分,从而导致信息丢失和失真。 若 $W$ 是理想低通信道的带宽,则极限波特率为 $2W$ (单位为 baud/s),若用 $V$表示每个码元离散电平的数据($V$ 种不同的电平可以最多表示 $log_2{V}$ 个比特),则极限传输率为 $2W \cdot log_2{V}$ (单位为 b/s)
香农定理 香农定理说明了在 有噪音干扰、带宽有限 的信道中的数据极限传输速率,当实际传输速率小于等于改速率时,可以做到不产生误差。
香农定理的核心思想是:
即使信道中存在噪声,只要信息传输速率低于某个极限值(即信道容量),就一定可以通过某种编码方式实现几乎无差错的传输。这个极限值取决于信道的带宽和信噪比。
香农用一个公式精确地描述了信道极限传输速率:
$$C = B * log_2(1 + \frac{S}{N})$$
其中:
$C$ 是信道容量,单位是比特每秒 (bps),表示信道理论上的最大传输速率。 $B$ 是信道带宽,单位是赫兹 (Hz),表示信道可用的频率范围。 $S$ 是信号功率,表示信号的强度。 $N$ 是噪声功率,表示信道中噪声的强度。 $\frac{S}{N}$ 是信噪比(Signal-to-Noise Ratio, SNR),通常以线性形式表示(不是分贝 dB)。 公式中的含义:
带宽 ($B$) 越大,信道容量 ($C$) 越大:这意味着更宽的信道可以传输更多的数据。 信噪比 ($\frac{S}{N}$) 越大,信道容量 ($C$) 越大:这意味着信号相对于噪声越强,传输速率就越高。 $S/N$ 信噪比有 线性比值 和 分贝(dB) 两种形式
线性比值: $$\frac{S}{N} = \frac{\text{信号功率}}{\text{噪声功率}}$$
分贝形式(dB): $$S/N_{dB} = 10 \cdot log_{10}{\frac{S}{N}}$$
反过来,从分贝值换算为线性比值:
$$\frac{S}{N} = 10^{\frac{S/N_{dB}}{10}}$$
出现在香农公式 $C = B * log_2(1 + \frac{S}{N})$ 中的 $\frac{S}{N}$ 是 线性比值,不是分贝!
2.2 - 编码和调制 需记住各种编码方法所对应的 0/1 表示,以及各种调制方法的概念,可能在选择题中考察。
在计算机网络中,编码和调制是数据传输的两个关键过程,它们的目标都是为了让数字信息(如二进制的 0 和 1)能够有效、准确地在物理介质(如双绞线、光纤、无线电波等)上传输。
编码类型 编码(encoding)指的是把数字信号(0 和 1)转换成适合在传输介质上传输的电信号或光信号。常见的编码方式有以下几种:
编码方法 1 的表示 0 的表示 归零编码(RZ) 在时钟周期内由高电平跳到低电平 在时钟周期中保持低电平 非归零编码(NRZ) 时钟周期内保持高电平 时钟周期内保持低电平 反向不归零编码(NRZI) 电平与上一个时钟周期保持一致 电平相比上一个时钟周期发生跳变 曼彻斯特编码(Manchester Encoding) 在时钟周期内由高电平跳到低电平 在时钟周期中由低电平跳到高电平 差分曼彻斯特编码(Differential Manchester Encoding) 电平变化与上一个时钟周期相反 电平变化相比上一个时钟周期一致
调制方法 指的是把编码后的数字信号转换为模拟信号(如正弦波),以适应物理信道(如无线电波)的传输。
调制方法主要了解以下四种:
ASK (幅度偏移键控 - Amplitude Shift Keying) FSK (频率偏移键控 - Frequency Shift Keying) PSK (相位偏移键控 - Phase Shift Keying) QAM (象限幅度调制 - Quadrature Amplitude Modulation) 调制技术 基本思想 表示方法例子 常见应用 ASK 通过改变载波的幅度表示数据 0: 无信号;1: 最大幅度的信号 光纤通信 FSK 通过改变载波的频率表示数据 0: 900 Hz;1: 901 Hz 低速无线通信、电话系统 PSK 通过改变载波的相位表示数据 0: 0°相位;1: 180°相位 高速无线通信,例如 Wi-Fi QAM 同时改变载波的幅度和相位表示数据 16 种不同的幅度和相位组合 数字电视、Wi-Fi、有线和无线通信系统
2.3 - 交换方式 掌握三种交换方式的发送方法,并且学会计算传输时延和传输时间,可能在选择题中考察。
交换 交换方式 是指在通信网络中,数据从发送方传输到接收方时,网络节点(如交换机、路由器)处理和转发数据的方式。它决定了数据传输的路径、资源分配和效率。交换方式是通信网络设计的核心,直接影响网络的性能、时延和资源利用率。
电路交换、报文交换和分组交换是三种主要方式,其中分组交换又可以进一步分为 数据报和虚电路 两种方式:
电路交换 电路交换(Circuit Switching)是一种传统的通信方法,其中在发送方和接收方之间建立一个专用的通信路径(电路),该路径在整个通信过程中保持不变,其过程如下:
连接建立 :发送方发起请求,通过交换设备(如电话交换机)在网络中为通信双方寻找并分配一条固定路径,建立端到端的专用电路。这需要信令系统协调。数据传输 :电路建立后,数据(语音、视频等)通过这条固定路径连续传输。整个通信期间,路径保持独占,即使没有数据传输,资源也不会释放。连接释放 :通信结束后,发送方或接收方发出终止信号,交换设备拆除电路,释放占用的资源(如带宽、端口)供其他用户使用。电路交换的典型应用是 传统电话网络(PSTN)。其优缺点如下:
优点:稳定性:一旦建立连接,通信是连续且稳定的。 低延迟:由于路径是专用的,数据传输没有竞争,延迟较低。 缺点:资源浪费:路径在整个通信过程中被独占,即使没有数据传输时,资源仍然占用。 建立时延:建立连接需要时间,初始延迟较高。 报文交换 报文交换(Message Switching)不需要建立专用路径,整个报文作为一个单元传输,节点存储并转发整个报文。其过程如下:
报文发送 :发送方将完整的数据消息(大小可变,可能包含文本、文件等)发送到网络中的第一个节点(通常是交换机或路由器)。存储转发 :每个节点接收整个报文,存储在缓冲区,检查目标地址后,选择下一跳节点转发。报文在网络中逐跳传输,直到到达接收方。接收与处理 :接收方收到完整报文后,进行处理或存储。报文交换主要用于早期的电报和一些数据网络中。报文交换的优缺点如下:
优点:灵活性:不需要建立专用线路,可以动态选择路径。 适应性:适合于突发性的数据传输。 缺点:高延迟:每个节点都需要存储和转发整个报文,增加了延迟。 资源占用:大报文可能占用较多的存储资源。 分组交换 分组交换(Packet Switching)将数据分成小的分组(或数据包),每个分组独立传输,并可能通过不同路径到达目的地。其过程如下:
数据分割 :发送方将消息拆分为多个分组,每个分组附带头部信息(如源地址、目标地址、序列号)。分组传输 :每个分组独立在网络中传输,节点(路由器)根据头部信息选择最佳路径,分组可能走不同路径到达目的地(动态路由)。存储转发 :每个节点接收分组,存储后快速转发到下一跳,分组大小小,处理速度快。重组与接收 :接收方收到所有分组后,根据序列号重新组装成原始消息。如果有分组丢失,可请求重传。分组交换已经广泛应用于互联网,比如当前的 IP 协议就是分组交换的一种实现。
报文(Message)和分组(Packet)的区别?
报文是一个完整的、不可再分的数据单元,通常包含一个完整的信息或者文件。
分组是将数据分割成较小的、固定大小的单位,每个单位可以独立传输。
如今互联网已经很少见到报文交换了,报文和分组时一种概念。IP 分组(Packet)就是分组的一种实现,如果没有网络层的话,UDP 的 Datagram 直接进入数据链路层,UDP 的 Datagram 就是一个报文(Message)。
分组交换是对报文交换的一种改进,它具备如下优点:
高效性:网络资源按需分配,多个通信可以共享同一物理路径。 鲁棒性:分组可以通过不同路径传输,网络故障时能自动选择替代路径。 适应性强:适合于多种类型的数据传输(语音、视频、数据等)。 其缺点与报文交换类似,由于分组可能通过不同路径到达,可能导致抖动和延迟。
对比 电路交换 通过建立专用物理电路实现连续数据传输,资源独占但效率低,适合实时通信如电话;报文交换 以整个消息为单位存储转发,无需预连接但时延高,适合低频大数据传输;分组交换 将数据拆分为小分组独立传输,资源共享且效率高,适合现代互联网,但需处理分组丢失或乱序问题。下图包含三种交换方式传输的时空图,横向表示距离,纵向表示时间:
需要能够图中的那一部分是 传播时间 ,哪一部分是 传输时间 ,这一部分内容可以和 数据链路层信道利用率 对比学习。
传输时间计算 电路交换 的传输时间包含 连接建立 和 数据传输的时间:
建立时间:在进行数据传输之前,需要建立一个专用的电路连接,这个过程会产生一定的延迟。设立连接时间为 $T_{\text{setup}}$。
传输时间:一旦电路建立,数据传输时间主要取决于数据量和带宽。传输时间 $T_{\text{transmission}}$ 可以用公式表示为:
$$ T_{\text{transmission}} = \frac{\text{数据大小}}{\text{带宽}} $$
总传输时间:总传输时间包括建立时间和传输时间:
$$ T_{\text{total}} = T_{\text{setup}} + T_{\text{transmission}} $$
报文交换 和 分组交换 的场景更加复杂一些,我们需考虑多种时延 以及 不同链路之间的带宽差异。
但是两者的思路类似,不同点在于报文和分组的大小不同,这里以分组交换来进行说明。
下面举一个比较全面的例子来说明一下,网络中有 A、B、C、D 四个结点,其中链路的带宽分别为 $B_1$、$B_2$、$B_3$。
在从结点 A 发送分组至结点 D 的过程中,总时间主要包含三种时延:传播时延、传输时间 和 排队时间。
首先,假设信号传播速度为 $\text{speed}$,A 到 D 之间的距离为 $L$,则:
$$\text{传播时延} = \frac{L}{\text{speed}}$$
假设每个分组的大小为 $P$,则 A → B 的传输时间为 $P / B_1$,B → C 的传输时间为 $P / B_2$,C → D 的传输时间为 $P / B_3$。由下图可知,不同链路间的分组传输存在流水线的 overlap 现象,A 向 B 发送完第一个分组后即可发送第二个分组。
在这种情况下,如果 A 向 D 传输 $k$ 个分组的话,则总传输时间受限于带宽最低的链路,若 $B_1$ 为链路最低的带宽的话,则:
$$\text{总传输时间} = \frac{k \times P}{B_1} + \frac{P}{B_2} + \frac{P}{B_3}$$
上述公式是一种特殊的情况,如果 $B_{i} < B_{j} < B_{k} < \cdots$ 的话,则
$$\text{总传输时间} = \frac{k \times P}{B_i} + \frac{P}{B_j} + \frac{P}{B_k} + \cdots \text{(一般情况)}$$
一般排队时间在试题中都不需要考虑,所以总时间为传输时间和传播时延之和:
$$\text{总时间} = \frac{L}{\text{speed}} + \frac{k \times P}{B_1} + \frac{P}{B_2} + \frac{P}{B_3}$$
数据报和虚电路 在 分组交换 中,根据分组的路由和连接方式,分组交换分为数据报(Datagram)和虚电路(Virutal Circiut)两种模式:
数据报 无连接 的分组交换方式,每个分组(数据报)独立传输,包含完整的源地址和目标地址,网络根据每个分组的头部信息动态选择路由路径。虚电路 面向连接 的分组交换方式,在通信开始前建立一条逻辑路径(虚电路),所有分组沿此路径传输,模拟电路交换的稳定连接。电路交换和虚电路的区别
电路交换:在通信开始前,为发送方和接收方建立一条 专用物理电路 ,整个通信期间独占该路径。数据通过固定路径连续传输,资源不共享。 虚电路:在 分组交换 网络中,模拟电路交换 的行为,通过逻辑路径(虚电路)传输数据。虚电路并非物理独占,而是通过协议在分组交换网络中建立的逻辑连接。 下表对比了数据报和虚电路的特性:
特性 数据报 虚电路 连接性 无连接,每个分组独立处理 有连接,建立虚电路后传输分组 路由 每个分组独立路由 虚电路建立后,沿着相同路径路由 通信开销 较低,不需要建立和维护连接 较高,建立连接需要额外开销 分组到达顺序 不保证分组到达的顺序 保证分组按照发送顺序到达 分组丢失 可能出现分组丢失,需要上层协议处理 较低的丢包率,可靠传输 带宽利用率 不需要预留带宽,按需使用 预留带宽,可能造成资源浪费 适用场景 Internet 中的 IP 数据包 电路交换、ATM 等有连接通信 例子 Internet 中的 IP 分组 早期电话网络、ATM 网络
数据报和虚电路是两种不同的通信服务模型,适用于不同的通信需求和网络类型。数据报适合于互联网等不保证可靠传输的环境,而虚电路适合于对可靠性要求较高的电路交换和 ATM 等网络。选择合适的通信模型取决于应用需求和网络设计。
2.4 - 物理层设备 了解物理层设备的概念即可,注意需要记住各种电缆类型的英文缩写。
集线器 定义 :集线器(Hub)是一个简单的物理层设备,用于将多台计算机或其他网络设备连接在一起,从而形成一个单一的网络段。
工作方式 :当一个设备通过集线器发送数据时,数据会被广播到集线器的所有其他端口。每个连接到集线器的设备都会收到这些数据,但只有目标设备才会处理它。集线器本身不会分析或查看传输的数据。
局限性 : 由于集线器将数据广播到所有设备,所以它可能导致网络拥塞。因此,在大型或流量较大的网络中,集线器已经被交换机所取代,交换机能够智能地将数据转发到目标设备。
中继器 定义 :中继器是一个物理层设备,用于放大或再生数字信号。
工作方式 :在以太网或其他类型的网络中,数据在电缆上只能传输一定的距离,超过这个距离,信号会减弱或退化。中继器放置在这种距离的两端,用于接收退化的信号,放大或再生它,然后将它传输到下一段电缆。
应用 :中继器被用于扩展网络的物理范围,超出了单一段电缆或物理媒体的限制。
网络适配器 定义 :网络适配器 (Network Adapter),也称为网络接口卡(NIC)或简称网卡,是一种硬件组件,用于连接计算机或其他设备到一个网络。
工作方式 :网络适配器为计算机提供了一个或多个网络连接端口,它将计算机的数字数据转换为可以在物理媒体(例如双绞线、光纤或无线电波)上传输的信号。同样,当信号从网络到达网络适配器时,它会将这些信号转换回计算机可以理解的数字数据。
物理地址 :每个网络适配器都有一个唯一的物理地址,称为 MAC 地址。这个地址在生产时被烧录到设备中,用于在局域网内唯一地识别设备。
电缆 双绞线 (Twisted Pair):双绞线由一对绝缘的铜线组成,两线之间呈螺旋形地绞在一起。 光纤 (Fiber Optic):光纤是由极细的玻璃或塑料纤维制成的,用于传输光信号。 同轴电缆 (Coaxial Cable):同轴电缆由一个中心铜导线、一个绝缘层、一个金属屏蔽和一个外部的塑料或橡胶覆盖层组成。 双绞线(twisted pair cable)的结构如上图所示,“双绞线”之所以叫“双绞线”,是因为它的结构真的就是两根绝缘铜线按照一定方式互相“绞”在一起。
这种“绞合”结构是为了抗干扰,让数据传输更加稳定可靠。
光纤(fiber optic)的结构如上图所示,光纤利用光在里面的反射来传输数据。相比电信号,它的抗干扰能力更强、传输速度更快、距离也更远,非常适合高速、远距离的数据通信。
3 - 数据链路层 在选择题中考察,个别年份也在大题中考察过,需熟练掌握介质访问控制的相关方法。
学习思维导图:
# 数据链路层
## 数据链路层的功能
## 组帧
## 差错控制
- 检错编码
- 纠错编码
## 流量控制和可靠传输机制
- 流量控制、可靠传输和滑动窗口
- 停等协议
- 回退N帧
- 选择性重传协议
## 介质访问控制
- 信道划分
- 随机访问:ALOHA, CSMA, CSMA/CD, CSMA/CA
- 轮询访问
## 局域网
- 基本概念和体系结构
- 以太网和IEEE 802.3
- 无限局域网和IEEE 802.11
- VLAN
## 广域网
- 基本概念
- PPP协议
## 数据链路层设备
- 以太网交换机和工作原理
数据链路层功能
封装数据帧(Frame Encapsulation):数据链路层将来自网络层的数据包封装成数据帧,这包括将源和目标地址添加到帧头部,以便在物理介质上的传输。 数据帧传输(Frame Transmission):数据链路层负责将数据帧从一个物理节点传输到另一个物理节点。这可能涉及到点对点的传输(例如,以太网)或多点广播传输(例如,Wi-Fi)。 物理地址寻址(Physical Addressing):数据链路层使用物理地址(通常是 MAC 地址)来标识设备。这些地址用于确定数据帧的目标设备。 帧同步和定界(Frame Synchronization and Framing):数据链路层确保接收端可以正确识别和分离不同的数据帧。这通常通过在帧的起始和结束位置使用特殊的比特模式来实现。 流量控制(Flow Control):数据链路层可以控制发送端的数据传输速率,以防止接收端不堪重负而丢失数据。这确保了适当的数据流量管理。 差错检测和纠正(Error Detection and Correction):数据链路层使用差错检测技术(如 CRC 校验)来检测帧在传输过程中是否受到损坏。一些数据链路层协议还可以进行错误纠正,尝试修复损坏的数据。 3.1 - 组帧 掌握几种组帧方法,重点掌握首位定界字符法、零比特填充法,可能在选择题中考察。
数据链路层的主要功能就是组帧。
帧(frame)代表数据链路层的数据发送单位,在接收到来自于网络层的报文(packet)时如何为其添加帧头和帧尾,并且以何种方式进行帧定界(接收方区别连续不同的帧)。
组帧的关键就在于帧定界,也就是对于接收方来说,它能够以某种方式区分连续收到的不同帧。
从这个角度出发,组帧方式可以被分为以下几种:
字符计数法 字符计数法在帧首部使用计数字段来表明帧内字符数量。
当接收方读取帧时,根据读取帧开头的一部分内容,即可得知当前帧的长度是多少,这样就
首位定界字符法 首位定界字符法即 使用特殊控制字符标志帧的开始和结束 。
但是使用这种方式可能出现如下问题:就是 首位定界字符 可能会在帧内部出现,这个时候就会造成歧义。
所以当特殊字符出现在帧的数据部分时,需要用转义字符ESC来对特殊字符进行转义,同样,ESC出现在数据部分同样需要转义。
以上图为例,假设我们使用 FLAG 作为首位定界字符的话(注意这里 FLAG 只是字符名称,不是表示字符是 FLAG),那么当 FLAG 出现在数据部分时,我们需要对 FLAG 进行转义,需要注意的是,因为我们使用 ESC 作为转义字符,所以当数据中出现 ESC 时,我们也需要对转义字符自己进行转义。
零比特填充法 零比特填充法(Bit Stuffing)与首位定界字符法思路类似。
用 01111110 作为一个新的数据帧的开头,这里的关键在于要对数据帧内容中与 01111110 相同的部分进行转义,转义的方式如下:
在 发送方 :每当数据中出现 连续 5 个 ‘1’ 时, 就自动插入一个 ‘0’,避免形成 6 个连续的 ‘1’(即避免形成 01111110)。 在 接收方 :每当检测到 连续 5 个 ‘1’ 后跟着一个 ‘0’,就去掉这个 ‘0’,还原原始数据。 在传送的比特流中可以传送任意比特组合,而不会引起对帧边界的判断错误。零比特填充法很容易由硬件来实现,性能优于字符填充法。 对于零比特填充法,需要记住 01111110 这种开头的比特填充方式 以及 具体如何进行转义。
违规编码法 违规编码法(Physcial Layer Coding Violations)使用特殊电平进行定界。比如,曼彻斯特编码将数据比特“1”编码为“高 - 低”电平,将比特“0”编码为“低 - 高”电平对,而“高 - 高”电平对和“低 - 低”电平对是没有被使用的,所以可以用这两个电平进行帧定界。
编码方式详见 编码和调制 。
3.2 - 差错控制 本节内容比较复杂,尤其是涉及到 CRC 和海明码的具体细节,掌握检错和纠错的大致流程即可,可能在选择题中考察。
分类 奇偶校验码 奇偶校验码(Parity Check Code)是一种简单高效的错误检测机制,广泛应用于数据传输和存储系统中,用于发现单比特错误。其核心思想是通过添加一个校验比特(parity bit),确保数据中“1”的总数符合特定的奇偶规则。
奇偶校验码有两种常见的类型:奇校验和偶校验。
奇校验 (Odd Parity):校验比特的值使数据(包括校验比特)中“1”的总数为奇数。 例如,若原始数据“1”的个数为偶数,校验比特设为 1;若为奇数,设为 0。 若接收端检测到“1”的总数为偶数,则说明传输中存在错误。 偶校验 (Even Parity):校验比特确保数据中“1”的总数为偶数。 例如,若原始数据“1”的个数为奇数,校验比特设为 1;若为偶数,设为 0。 若接收端检测到“1”的总数为奇数,则表明数据出错。 奇偶校验码的 工作原理 如下:
发送端 :根据奇校验或偶校验规则,计算原始数据中“1”的个数,设置校验比特,并将数据连同校验比特一起发送。接收端 :检查接收到的数据(包括校验比特)中“1”的总数是否符合预设的奇偶规则。若不符合,说明传输过程中可能发生了单比特错误。奇偶校验的工作原理是发送端计算数据中所有比特的总数,并根据所选的奇偶性规则设置校验比特的值。接收端在接收数据后再次计算所有比特的总数,包括校验比特,然后检查总数是否满足所选的奇偶性规则。如果总数不符合规则,接收端将检测到错误。
循环冗余码 循环冗余校验(CRC)是一种常用的数据完整性校验方法,主要用于数据传输的错误检测。CRC 的核心思想是将数据看作多项式的系数,并用特定的生成多项式进行除法操作,得到的余数即为 CRC 值。
校验流程 CRC 校验大致流程如下:
生成多项式:CRC 的核心是一个生成多项式,通常用二进制表示。这个多项式是事先定义好的,并且在发送端和接收端都必须知道。 帧校验码计算:为了计算 CRC 校验码,发送端将数据帧和生成多项式进行除法运算,得到余数,然后将余数附加到数据帧的末尾。如果生成多项式是 n 位长,那么 CRC 校验码将是 n-1 位长。 传输:将 CRC 校验码附加到数据帧的尾部,发送至接收端。 接收端校验:接收端接收到数据帧后,也执行相同的 CRC 校验操作。它将接收到的数据帧与生成多项式进行除法运算,得到一个余数。如果余数为零,表示数据帧没有错误。如果余数不为零,表示数据帧存在错误。 zero accept
实例 假设我们要发送的数据是:1010001101
我们选择的生成多项式是:110101,对应的是 $x^5 + x^4 + x^2 + 1$
发送方操作:
为了进行校验码计算,首先在原始数据的尾部添加 k−1 个零(其中 k 是生成多项式的位数,这里是 4),所以数据变成了:1010001101 00000 使用生成多项式除以这个新的数据。实际上,我们使用二进制的异或操作来进行模 2 除法。 计算得到的余数就是 CRC。 110101011
------------------
110101 | 101000110100000
110101
------
111011
110101
------
111010
110101
------
111110
110101
------
101100
110101
------
110010
110101
------
01110
将计算得到 CRC 01110 添加到数据后面一起发送,接收方接收到的数据为 101000110101110
接收方接收到数据后进行校验,计算过程如下:
110101011
--------------------------------------
110101 | 101000110101110
110101
------
111011
110101
------
111010
110101
------
111110
110101
------
101111
110101
------
110101
110101
------
0
计算得到余数为零,表示数据帧没有错误。
用异或进行 CRC 计算
当我们在 CRC 计算中“减去”一个多项式,我们实际上是使用异或操作来模拟这个减法。因为在二进制中,减法和加法都可以使用异或操作来完成(只要没有进位)。具体来说,对于无进位的情况,1-1 = 0、0-0 = 0、1-0 = 1 和 0-1 = 1,而这些结果与使用异或得到的结果是相同的。
因此,在 CRC 计算中,当生成多项式与被除数的相应部分对齐时,我们可以使用异或操作来模拟减去生成多项式的操作。然后,我们继续这个过程,直到处理完所有的位。
海明码 海明码(Hamming Code)是一种用于错误检测和纠正的编码方案,通常用于数据传输和存储系统中。它的主要目标是检测和纠正数据中的单比特错误。
海明码的核心思想是在数据位之间插入一定数量的校验位(也称为奇偶校验位),使得每个校验位都负责检查一组特定的位。校验位的数量取决于数据位的数量,并且它们的位置通常是 2 的幂次(即第 1 位、第 2 位、第 4 位……)。
生成过程 以一个 实例 说明海明码的 生成和纠正 过程:
假如我们的数据是 $1011$ ,也就是 $4$ 位。根据海明码的原则,我们需要确定足够的校验位 $r$ 来满足以下条件:
$2^r \ge k + r + 1$
对于 $k = 4$ (数据位),我们找到最小的 $r$ 为 $3$
对于 $k$ 位数据,应该有多少位校验位
假设我们有 $k$ 位数据,我们需要添加 $r$ 位校验位,那么校验位的总数必须满足以下条件:
所有数据位和校验位的总数加起来可以由校验位来表示。也就是说,每一位数据位和校验位在位模式中都有一个唯一的表示。这意味着 $2^r$ 必须至少等于 $k+r+1$,其中加 $1$ 是因为校验位模式全为零(即没有错误)的情况也必须被考虑在内,即
$2^r \ge k + r + 1$
首先将校验位( $p$ )插入到数据位中的适当位置。校验位下标是 $2$ 的幂( $1, 2, 4, 8, …$ )。
第 $1 (2^0)$ 位:校验位 $p_1$ 第 $2 (2^1)$ 位:校验位 $p_2$ 第 $4 (2^2)$ 位:校验位 $p_3$ 然后再放置剩余的数据位 $d$ :
第 $3$ 位:数据位 $d_1$ 第 $5$ 位:数据位 $d_2$ 第 $6$ 位:数据位 $d_3$ 第 $7$ 位:数据位 $d_4$ 位置 7 6 5 4 3 2 1 海明码 $d_4$ $d_3$ $d_2$ $p_3$ $d_1$ $p_2$ $p_1$ 数据 1 1 0 - 1 - -
注意到上述我们提到的关于校验位和数据位的第 $n$ 位,下标是从 1 开始 而不是 0 开始的。
首先给出位置下标的二进制表示:
位置 7 6 5 4 3 2 1 二进制 111 110 101 100 011 010 001
$p_1 $ 检查位置 $1$ 、 $3$ 、 $5$ 、 $7$ 的位(最低位为 1) 。所以 $p_1 = d_1 \oplus d_2 \oplus d_4 = 1 \oplus 0 \oplus 1 = 0$ ,所以 $p_1 = 0$ 。 $p_2 $ 检查位置 $2$ 、 $3$ 、 $6$ 、 $7$ 的位(次低位为 1)。这些位的异或值为 $p_2 = d_1 \oplus d_3 \oplus d_4 = 1 \oplus 1 \oplus 1 = 1$,所以 $p_2 = 1$ 。 $p_3 $ 检查位置 $4$ 、 $5$ 、 $6$ 、 $7$ 的位(最高位为 1) 。这些位的异或值为 $p_3 = d_2 \oplus d_3 \oplus d_4 = 0 \oplus 1 \oplus 1 = 0$,所以 $p_3 = 0$ 。 位置 7 6 5 4 3 2 1 海明码 $d_4$ $d_3$ $d_2$ $p_3$ $d_1$ $p_2$ $p_1$ 数据 1 1 0 0 1 1 0
所以, $1011$ 的 $(7,4)$ 海明码是 $0110011$ 。任何一位的单一错误都可以通过分析校验位来检测并纠正。
检测和纠错 还是以 上文的例子 来说明海明码检测和纠错的过程。
假设在传输过程中第二位出现了错误,接收的码变为 $0010011$ 。
首先,接收者现在要 重新计算校验位 :
$p_1$(位置 1):检查二进制最低位为 1 的位置(1, 3, 5, 7),即 $p_1, d_1, d_2, d_4$$p_1’ = 0 \oplus 1 \oplus 0 \oplus 1 = 0$ 接收到的 $p_1 = 0$,所以 $p_1’ = p_1$,无错误 $p_2$(位置 2):检查二进制第二位为 1 的位置(2, 3, 6, 7),即 $p_2, d_1, d_3, d_4$$p_2’ = 0 \oplus 1 \oplus 1 \oplus 1 = 1$ 接收到的 $p_2 = 0$,所以 $p_2’ \ne p_2$,有错误 $p_3$(位置 4):检查二进制第三位为 1 的位置(4, 5, 6, 7),即 $p_3, d_2, d_3, d_4$$p_3’ = 0 \oplus 0 \oplus 1 \oplus 1 = 0$ 接收到的 $p_3 = 0$,所以 $p_3’ = p_3$,无错误 可以看到有错误发生,接下来需要 生成错误模式 :
$$(p_1’ \oplus p_1, p_2’ \oplus p_2, p_3’ \oplus p_3) = (0 \oplus 0, 1 \oplus 0, 0 \oplus 0) = (0, 1, 0)$$
错误模式为二进制 010,十进制值为 2,表示错误在位置 2(即 $p_2$)。
最后一步是 纠正错误 :位置 2 的值 $p_2$ 从 0 翻转为 1,得到纠正后的码字:
位置 7 6 5 4 3 2 1 海明码 $d_4$ $d_3$ $d_2$ $p_3$ $d_1$ $p_2$ $p_1$ 修改前 1 1 0 0 1 0 0 修改后 1 1 0 0 1 1 0
现在,海明码回到了正确的 $0110011$ 状态。
海明距离 海明距离(Hamming Distance,也译作汉明距离)是指两个等长编码(码字)之间对应位置上不同比特的个数。它是衡量编码差异的指标,用于分析编码集的错误检测和纠正能力。
编码集 编码集 是指在数据通信或存储系统中用于表示信息的一组码字(codewords)。每个码字是一个固定长度的比特序列,设计目的是通过添加冗余比特来检测或纠正传输过程中的错误。编码集的检测和纠错能力主要由其 最小海明距离 决定:
最小海明距离是编码集中任意两个不同码字之间海明距离的最小值,记为 $d$。它反映了编码集的“分散性”:$d$ 越大,码字之间的差异越大,编码集的错误检测和纠正能力越强。
最小海明距离为 $d$ 的编码集具备如下能力:
检错能力 :最多可以检测 $d-1$ 位错误。纠错能力 :最多可以纠错 $\lfloor (d - 1) / 2 \rfloor$。海明码的最小汉明距离是 3。
海明码可以纠正 1 位错误。通过计算伴随式(syndrome),接收端能够准确识别并纠正数据中单个比特的错误。
海明码可以检测最多 2 位错误。当发生 2 位错误时,伴随式会指示错误的存在,但无法准确纠正(因为可能与纠正 1 位错误的模式混淆)。
3.3 - 流量控制 掌握停等、回退 N 帧、选择性重传的过程以及窗口大小,可能在选择题中考察。
停等协议 停等 (Stop-and-Wait) 是一种基础的自动重传请求 (ARQ) 协议。其基本思想是在发送每个数据帧后都停下来,等待接收方的确认。只有在收到确认后,发送方才会继续发送下一个帧。由于这种方法在任何时刻只允许一个帧在传输中,因此它被称为“停等”。
过程关键:
发送数据 :发送方发送一个数据帧到接收方,并启动一个计时器等待确认。等待确认 :发送方在发送数据帧后处于等待状态,直到接收到确认或计时器到期。确认的接收 :接收方在收到数据帧后,检查其完整性(例如通过校验和)。如果数据帧正确,接收方会发送一个确认帧回到发送方。计时器到期 :如果发送方的计时器在收到确认之前到期,发送方会假设数据帧丢失或确认丢失,并重新发送数据帧。然后再次启动计时器。回退 N 帧 在 回退 N 帧(GBN, Go Back N)协议中,发送方可以连续发送多个帧,而不需要等待每个帧的确认。但是,发送方需要为每个帧维护一个计时器。如果一个帧的计时器到期而没有收到确认,发送方会重新发送该帧及其之后发送的所有帧。
过程关键:
窗口大小 :在 GBN 中,若帧序号的比特数为 $n$,则发送窗口的最大值为 $2^n - 1$,接受窗口的大小为 $1$。发送过程 :发送方连续发送窗口内的帧,每发送一个帧,都会为其启动一个计时器。接收过程 :接收方只接收期望的帧序号。如果接收到的帧是期望的,它会发送一个确认。如果接收到的帧不是期望的(可能是由于前面的帧丢失),它会丢弃该帧并重新发送对上一个正确接收的帧的确认。超时和重传 :
发送方通常只为 最早发送但未确认的帧(窗口内的第一个未确认帧)设置一个单一的超时定时器。
如果计时器到期,该帧及其之后发送的所有帧都会被重传。重传的原因是,如果一个帧丢失,后续的帧虽然可能已经到达接收方,但由于接收方的窗口大小为 1,它们会被丢弃。滑动窗口 :当发送方收到一个帧的确认,它知道该帧及其之前的所有帧都已正确接收。于是,它会将窗口向前滑动,从而可以发送新的帧。通过 GBN, SR 交互演示 你可以更好理解 GBN、SR 的过程。
选择性重传 选择性重传 (SR,Selective Repeat)是另一种自动重传请求 (ARQ) 协议,它旨在解决回退 N 帧协议在高误码率环境下的效率问题。与 Go-Back-N 不同,Selective Repeat 只重传那些确实丢失的帧,而不是所有之后的帧。这使得 SR 在高误码率环境下比 GBN 更为高效。
过程关键:
窗口大小 :在 SR 中,一般发送窗口和接受窗口大小一致,若帧序号的比特数为 $n$,则窗口大小最大为 $2^{n-1}$。发送过程 :发送方连续发送窗口内的帧,并为每个发送的帧启动一个计时器。接收过程 :接收方接收所有在其窗口范围内的帧,并为正确接收的每个帧发送确认。接收到的帧可能是乱序的,但接收方可以缓存这些乱序的帧,直到可以按正确的顺序将其传递给上层。超时和重传 :如果发送方的某个帧的计时器到期,只有这个特定的帧会被重传,而不是所有的帧。这是 SR 与 GBN 的主要区别。滑动窗口 :发送方和接收方的窗口都是动态移动的。当发送方收到一个帧的确认时,它会尝试滑动其窗口以发送新的帧。同时,接收方在将帧按正确顺序传递给上层后,也会滑动其窗口。处理冲突的确认 :考虑到网络的延迟,发送方可能在超时并重传一个帧后才收到其早期版本的确认。为了处理这种情况,SR 协议需要具有识别和丢弃重复确认的机制。对比 停等协议(Stop-and-Wait)、GBN(Go-Back-N)、SR(Selective Repeat)是计算机网络中用于可靠数据传输的三种流量控制和错误处理协议。它们的主要目标是确保在不可靠的通信信道上的数据传输的可靠性。
重点注意接收方和发送方的窗口大小范围。
特性 停等协议 GBN 协议 SR 协议 发送方窗口大小范围(序号位数为 n) 1 最大为$2^n - 1$ 最大为$2^{n-1}$ 接收方窗口大小范围(序号位数为 n) 1 $1$ 与发送方窗口一致 发送方效率 低(每帧等待确认) 高(并发发送多帧) 高(并发发送多帧) 接收方效率 高(无需缓存多帧) 低(需要缓存多帧) 高(需要缓存多帧) 错误处理 重传单个丢失帧 重传从丢失帧开始的所有帧 重传单个丢失帧或乱序帧 带宽利用率 低 高(部分带宽利用) 高(部分带宽利用)
窗口大小限制 $$\text{发送窗口大小} + \text{接受窗口大小} \le 2^n$$
滑动窗口协议是计算机网络中用于控制传输层数据流的一种机制。在这种协议下,发送窗口和接收窗口的大小有一个重要的限制,即它们的和不能超过序列号空间的大小。序列号空间是由能够用于标识帧的序列号的总数确定的,这通常是由序列号的位数决定的。
对于一个使用了 $n$ 位序列号的协议,序列号的范围是从 $0$ 到 $2^n-1$ 。因此,整个序列号空间的大小是 $2^n$ ,这意味着理论上最多可以有 $2^n$ 个不同的帧在传输中被唯一区分。
这个限制的主要原因是防止所谓的“序列号回绕”(Sequence Number Wraparound)。如果发送窗口和接收窗口的大小之和大于序列号空间的大小,那么就可能发生一个新的帧使用了一个老的、已经被使用的序列号,但是该帧可能还在网络中传输或者被延迟。接收方将无法区分这是一个新的帧还是重复的帧。
信道利用率 在 ARQ 协议中,信道利用率(也叫做链路利用率)是指信道用于传输有效数据的效率,通常定义为 成功传输数据的时间占总传输时间的比例 。它反映了协议在给定信道条件下的性能,是评估 ARQ 协议效率的重要指标。
信道利用率 $U$ 可以表示为
$$U = \frac{T_{data}}{T_{total}}$$
其中:
$T_{data}$:成功传输有效数据的时间。 $T_{total}$:总时间,包含数据传输、确认、重传以及等待。 一般情况 对于 ARQ 协议,假设信号传播时间为 $T_p$,一个数据帧的传输时间为 $T_d$,一个确认帧的传输时间为 $T_a$,发送窗口的最大值为 $N$,信号往返时间 $RTT = 2 \cdot T_p$。
在此情况下,信道利用率 $U$ = 发送数据的时间 / 从发送第一个帧的时间到收到第一个确认帧的时间:
$$U = \frac{N \cdot T_d}{RTT + T_d + T_a}$$
停等协议 对于停等协议,信道利用率为
$$U = \frac{T_d}{RTT + T_d + T_a}$$
连续 ARQ 协议 对于使用了滑动窗口的协议(比如回退 N 帧和选择性重传),一次性可以传输 $N$ 个数据帧,信道利用率为
$$U = \frac{N \cdot T_d}{RTT + T_d + T_a}$$
注意有些时候确认帧比较小,在这种情况下确认帧传输时间 $T_a$ 可以忽略。
此外,$U \le 1$,所以当 $N \cdot T_d > RTT + T_d + T_a$ 时,信道利用率 $U = 1$。
3.4 - 介质访问控制 需熟练掌握信道划分以及随机访问信道控制的各种方式,在选择题中会考察。除此外,需理解 CSMA/CD 的细节,在往年真题的大题中也考察过。
共享介质 在介绍 MAC 概念之前,必须要说明一下共享介质的概念。
在一个网络环境中,多个设备可能需要同时访问同一个物理介质来发送数据,这个介质可以是电缆、光纤或者无线信道。
当设备发送数据时,数据包会在整个介质上传播,所有连接到该介质的设备都可以接收到数据包。如果多个设备同时发送数据,介质上的数据信号就会相互冲突进而导致错误。
所以 MAC 协议确保了 共享介质上的 有效、公正且有序的数据传输。
MAC 方式总结 介质访问控制(MAC,Media Access Control)可以分为 信道划分 以及 随机访问 两种大方向。
信道划分介质访问控制 也叫做多路复用,在一条传输介质上同时传输多个不同种类的信号(种类可以根据不同的参数进行划分),这样不同的设备可以发送特定类型的信号,并且不同信号之间相互不干扰,信道划分 访问控制可以分为以下几种:
FDM:频分多路复用 TDM:时分多路复用 WDM:波分多路复用 CDM:码分多路复用 随机访问介质访问控制 指多台设备共享同一个通信介质时,它们可以随机地尝试发送数据,而不需要事先协调,当发生冲突后再做后续的协调,以保证不会接收到错误的数据。
多路复用 多路复用(Multiplexing)是一种技术,用于在同一传输介质上同时传输多个信号,包含频分多路复用(FDM)、时分多路复用(TDM)、波分多路复用(WDM)和码分多路复用(CDM)四种。
FDM 频分多路复用(FDM)将可用带宽划分为若干个不重叠的频段,每个信号占用一个频段。各个信号可以同时传输,但彼此之间不会干扰,因为它们占用不同的频率。
FDM 在传统的模拟电话系统和广播中广泛使用。
TDM 时分多路复用(TDM)将时间划分成若干个时隙,每个信号在不同的时隙中传输。所有信号在时间上轮流使用同一传输介质。
TDM 常用于数字通信系统,如数字电话网络。
WDM 波分多路复用(WDM)是 FDM 的一种应用,主要用于光纤通信。它将光纤的可用带宽划分为多个波长(颜色),每个信号占用一个波长。
WDM 技术可以大幅增加光纤的通信容量,广泛应用于长距离和高速光纤网络。
CDM 码分多路复用(CDM)使用不同的编码来区分各个信号。所有信号可以在同一频带上同时传输,但通过使用不同的编码序列来避免相互干扰。
虽然 CDM 的概念可以用在许多不同的传输系统中,但在实践中,它主要作为 码分多址 (CDMA ,Code Division Multiple Access)的基础技术。
CMDA 在 CDMA 中,每一个比特时间划分为 m 个短的时间槽,称为码片(chip),每个站被指派一个惟一的 m bit 码片序列 (chip sequence) 。
如果发送比特 1,则发送自己的 m 位码片序列。 如果发送比特 0,则发送该码片序列的二进制反码。 简单理解就是,A 站向 C 站发出的信号用一个向量来表示,B 站向 C 站发出的信号用另一个向量来表示,两个向量要求相互正交。向量中的分量,就是所谓的码片。
当两个或多个站点同时发送时,各路数据在信道中线性相加。为了从信道中分离出各路信号,要求各个站点的码片序列相互正交。
令向量 $S$ 表示站 S 的码片向量,令 $T$ 表示其他任何站的码片向量。两个不同站的码片序列正交,就是向量 $S$ 和 $T$ 的规格化内积(inner product)都是 0:
$$S \cdot T = \frac{1}{m} \sum_{i=1}^{m}{S_i T_i} = 0$$
任何站的码片向量和该码片反码的向量的规格化内积都是 -1:
$$S \cdot \overline{S} = \frac{1}{m} \sum_{i=1}^{m}{S_i \cdot \overline{S_i}} = 0$$
举个实际的例子来说明。令向量 $S$ 表示 A 站的码片向量,$T$ 表示 B 站的码片向量。假设 A 站的码片序列被指派为
00011011,则 A 站发送 00011011 就表示发送比特 1,发送 11100100 就表示发送比特 0。为了方
便计算,将码片中的 0 写为 -1,将 1 写为 +1,因此 A 站的码片序列是 (-1 -1 -1 +1 +1 -1 +1 +1)。
令 $T$ = (-1 -1 +1 -1 +1 +1 +1 -1),可以观察到,不管是 $T$ 还是 $\overline{T}$,都有四个码片的值与 $S$ 相反,所以 $S \cdot T = 0$。
当 A 站向 C 站发送数据 1 时,就发送了向量 (-1 -1 -1 +1 +1 -1 +1 +1)。
当 B 站向 C 站发送数据 1 时,就发送了向量 (+1 +1 -1 +1 -1 -1 -1 +1)。
两个向量在公共信道上叠加,实际上是线性相加,得到 $S + \overline{T}$ = (0 0 -2 2 0 -2 0 2)。
ALOHA 协议 ALOHA 协议是一种早期开发的随机访问协议,用于在共享信道上传输数据。ALOHA 有两种基本类型:纯 ALOHA 和时隙 ALOHA。
纯 ALOHA:用户可以在任何时间发送数据包。由于没有时间同步,数据包之间容易发生冲突。 时隙 ALOHA:时间被分成离散的时隙,用户只能在时隙的开始发送数据包。这种方法通过同步发送时间,减少了冲突的概率。 纯 ALOHA 纯 ALOHA(Pure ALOHA)是一种简单的随机接入协议,允许用户在任意时刻发送数据包,而无需对时间进行任何同步或分时。
由于用户可以在任何时间发送数据包,数据包之间可能会发生冲突。
Station1 Station2 Station3 Station4 Frame 1.1 Resend Frame 1.2 Frame 2.1 Resend Frame 3.1 Resend Frame 4.1 Frame 2.1 Frame 4.1 Frame 3.1 Collision... Collision... Resend Text is not SVG - cannot display 工作原理:
用户随时发送数据包。 如果数据包成功到达接收端,则传输完成。 如果发生冲突(即两个或多个用户同时发送数据包),相关用户需要等待随机的时间后重传。 时隙 ALOHA 时隙 ALOHA(Slotted ALOHA)在纯 ALOHA 的基础上引入了时间同步,将时间划分为一系列等长的时隙。用户只能在时隙的开始发送数据包。
Station1 Station2 Station3 Station4 Frame 1.1 Frame 1.2 Frame 2.1 Resend Frame 3.1 Resend Frame 4.1 Frame 2.1 Frame 4.1 Frame 3.1 Slot 1 Resend Slot 2 Slot 3 Slot 4 Slot 5 Slot 6 Text is not SVG - cannot display 工作原理:
时间被划分为等长的时隙。 用户在时隙的开始时发送数据包。 如果一个时隙内只有一个用户发送数据包,则传输成功。 如果多个用户在同一时隙发送数据包,发生冲突,相关用户等待随机时间后重传。 CSMA 协议 CSMA(Carrier Sense Multiple Access)的中文叫做 载波监听多路访问,理解 CSMA 的关键在于理解它的名称中的两个部分:载波监听 以及 多路访问:
载波监听(Carrier Sense):因为 CSMA 是随机访问介质控制的一种方式,所以在发送数据前,必须确定当前通信介质中没有其他设备正在发送数据。所以载波监听可以被理解为以太网口内部芯片自带的一种功能,具体而言就是一种可以监听 信道在当前位置是否有数据传输的 的一种功能。 多路访问(Multiple Access):多个设备可以访问同一个通信介质。这意味着在任何给定时间,任何设备都可以尝试发送数据。 所以 CSMA 可以理解为 通过 载波监听 避免冲突,进而实现共享介质上的 多路访问 。
以下图为例,A、B、C、D 分为是连接到同一共享介质上的不同设备,当 A 开始发送数据时,B、C、D 分别会在不同的时刻监测到信号,具体的时刻为 设备与 A 之间的距离 / 信号传播速度。
这里需要深入理解 传播时延和传输时间 这两个概念:
传输时延(propogation time) = 距离 / 信号传播速度 传输时间(transmission time) = 数据大小 / 数据传输速率 CSMA 的问题在于它无法处理碰撞,当一个设备监听到当前介质中无信号时,它就可以发送数据,但监听得到的结果可能是 “假结果” 。因为有可能其他设备已经发送信号了,只是信号由于传播时延还没有到达当前设备。
所以假设当前设备监听得到了“假结果”,那么此时发送数据后介质上就会发生冲突。比如假设 C 在 A 的信号到来之前检测得到假结果,然后发送帧,这个时候信道中就会出现冲突:
那么 CSMA 如何处理冲突呢?
CSMA 不具备碰撞处理的功能,冲突处理是 CSMA/CD 的功能。这意味着在 CSMA 中,设备不会主动检测到碰撞。
所以实际应用中基本没有使用 “纯CSMA” 的协议,因为因为它 只监听信道是否空闲 ,但:
不能检测冲突 (如 CSMA/CD)也不避免冲突 (如 CSMA/CA)一旦多个设备在信道刚空时同时发送,必然冲突,没有机制处理 这在真实网络中会导致高碰撞率和低效率。
实际应用的都是 CSMA 的变种:
协议 是否实际应用 应用场景 特点 CSMA ❌ 几乎没有 教学概念 只监听,不检测、不避免、不重传 CSMA/CD ✅ 是 有线以太网(Ethernet) 监听 + 冲突检测 + 退避 CSMA/CA ✅ 是 无线局域网(Wi-Fi) 监听 + 冲突避免 + ACK确认
三种类型 CSMA 也 根据其在信道空闲时的行为分为三种类型,如下所示:
特征 1-persistent CSMA Non-persistent CSMA p-persistent CSMA 信道空闲时的行为 立即开始传输数据 立即开始传输数据 根据概率 p 决定是否传输数据 信道忙时的行为 立即开始传输数据 等待一个随机时间后重新监听 根据概率 p 决定是否重新监听 碰撞的可能性 高(当多个设备同时监听信道) 低(等待随机时间片段) 中等(取决于 p 的值和竞争情况) 等待时间 无等待 随机等待时间片段 随机等待时间片段 适用性 适用于低碰撞概率,高速局域网 适用于高碰撞概率,低速局域网 适用于中等碰撞概率和速率的局域网
CSMA/CD 协议 CSMA/CD(CSMA with Collision Detection,载波监听多路访问/碰撞检测)是 CSMA 的一种拓展,在了解这个知识之前,请确保你已经理解了什么是 CSMA 中的 CS(Carrier Sense 即 载波监听),以及什么是 CSMA 中的 MA(Multiple Access 即 多路访问)。
CSMA/CD 比 CSMA 多出一个 CD(Collision Detection 即 碰撞检测)的功能。
在上文中我们提到,CSMA 中监听到信道空闲可能是“虚假的”,所以在 CSMA 发送数据后介质中也许会发生冲突,但 CSMA 只能依靠非常原始的方案处理冲突。
CSMA/CD 就高级一些,在发送数据期间,我们刚刚提到的 监测器件(Carrier,就是 CSMA 中 C 的简称)会一直监听有没有冲突发生,
如果有冲突的话,就等待一段随机的时间,然后重试以上过程,并且发送一个特殊信号告诉其他设备发生了冲突。
以上图为例,假设 A 向 D 发送一段数据,C 向 A 发送一段数据,我们可以观察到:冲突发生的时间点 和 设备检测到冲突的时间点是不同的。
当 A 和 C 检测到冲突发生时,它们会立即停止发送,并且发送信号通知其他设备该次碰撞:
流程 CSMA/CD 的工作流程如下:
准备发送:适配器从网络层获得一个分组,封装成帧,放入网络适配器缓存准备发送。 检测信道:监听信道是否空闲,若信道空闲,则开始发送该帧;若信道忙,则持续检测直至信道空闲。 在发送过程中,适配器仍然持续检测信道。这里只有如下两种可能。发送成功:在争用期内一直未检测到冲突,该帧肯定能发送成功。 发送失败:在争用期内检测到冲突,此时立即停止发送,并且广播碰撞通知信号。接着适配器执行指数退避算法,
等待一段随机时间后返回到步骤 2。若重传 16 次仍不能成功,则停止重传并向上报错。 指数退避算法 在随机访问网络中,当冲突发生后,设备需要等待一段时间后重试发送,以避免再次冲突。
指数退避算法(Exponential Backoff Algorithm)通过动态调整等待时间,减少连续冲突的概率,提高网络效率。
其核心思想是当冲突发生时,设备随机选择一个等待时间,并在每次冲突后成倍增加等待时间范围,以降低后续冲突的可能性。
指数增长规则 如下:
如果是第 $k$ 次重传尝试(通常从 $k=1$ 开始),则从以下范围随机选择等待时间槽(slot)的个数: $$[0, 2^k - 1]$$
每个时间槽长度为一个基本单位(如 51.2 微秒,以太网中一个“slot time”)。 最大的 $k$ 通常是有限制的,例如以太网中最大为 10(即窗口最多增长到 $2^{10} - 1 = 1023$) 如果尝试达到一定次数仍冲突,放弃传输并上报错误。
举个实际例子:
假设某设备在尝试发送时检测到冲突:
第 1 次重试:在 [0, 1] 中随机选择一个时间槽(即可能等待 0 或 1 个 slot time)。 第 2 次重试:在 [0, 3] 中随机选择(0~3 个 slot)。 … 第 10 次重试:在 [0, 1023] 中随机选择。 第 16 次重试后仍失败:报错放弃。 限制条件 CSMA/CD 可以使用的限制条件 :帧的传输时延至少要两倍于信号在总线上的传播时延
为了在一个帧的发送过程中检测到冲突,发送站必须在整个帧发送完毕之前收到冲突信号。如果一个站点在发送完整个帧后才能检测到冲突,那么冲突的数据就已经在网络上传输完毕了,这样无法避免数据的损坏。
这种机制是基于这样一个事实:冲突的信号需要在网络上传播并被发送站检测到,发送站才会知道发生了冲突。因此,如果帧的传输时延太短,发送站可能在信号冲突返回之前就已经发送完毕了帧,导致无法检测到冲突。为了确保冲突能够被检测到,必须要求帧的传输时间足够长,以便在帧发送结束前,冲突信号能够返回到发送站。
最小传输时长 = 2 ×最大传播时延
最小帧大小 = 带宽 ×最小传输时长
B 在 A 发送的信号刚到达的前一瞬间 开始发送数据
A 必须还在传输数据,也就是说数据传输还没有结束, 才能在这个时刻检测到冲突
CSMA/CA 协议 CSMA/CD 适用于以太网(使用有线连接的局域网),但在无线局域网(WLAN,Wireless LAN)中无法直接使用 CSMA/CD,主要有以下原因:
无线设备不能同时“听”和“说”:无线收发器在发送数据时,无法同时监听信道来判断是否发生碰撞。 信道干扰比有线环境严重:无线信号受环境干扰更大,误判空闲或碰撞的概率更高。 隐藏节点问题(隐蔽站):假设 A 和 C 两台无线设备都想给 B 发送数据,但 A 和 C 彼此“看不到”,只看到 B 是空闲的。结果就是 A 和 C 同时给 B 发送,发生碰撞,但它们却以为没事。 为此,802.11 标准定义了广泛用于无线局域网的 CSMA/CA 协议,它对 CSMA/CD 协议进行修改,将冲突检测改为冲突避免 (Collision Avoidance,.CA)。“冲突避免”并不是指协议可以完全避免冲突,而是指协议的设计要尽量降低冲突发生的概率。
流程 侦听信道 (Carrier Sense)设备在发送数据前通过物理侦听(检查信道电信号)和虚拟侦听(NAV,网络分配向量,记录信道占用时间)判断信道是否空闲。若信道忙碌,设备进入退避机制,等待随机时间后再次侦听,以降低碰撞风险。 发送请求 (RTS,Request to Send)若信道空闲超过特定时间(DIFS,分布式帧间间隔),设备可发送 RTS 帧,通知其他设备其传输意图及所需时间。RTS 帧是可选的,主要用于较大数据包或高干扰环境。 清除发送请求 (CTS,Clear to Send)接收设备在确认信道空闲后(等待 SIFS,短帧间间隔),回复 CTS 帧,确认传输许可并通知附近设备保持沉默。CTS 帧增强了信道保护,减少隐藏节点问题。 数据传输 发送设备收到 CTS 帧后(等待 SIFS),开始传输数据帧。其他设备通过 NAV 设置避免干扰,确保信道专用于当前传输。 确认帧 (ACK,Acknowledgment)接收设备成功接收数据后(等待 SIFS),发送 ACK 帧确认。若发送端未收到 ACK(可能因碰撞或干扰),启动重传机制,重新执行上述步骤。 根据以上过程我们可以观察到 CSMA/CA 的一些关键特点:
碰撞避免 :CSMA/CA 通过侦听、RTS/CTS、退避机制预测和确认机制并避免碰撞,而非像 CSMA/CD(以太网)那样检测碰撞后处理,适合无线网络因其难以实时检测碰撞。隐藏节点问题 :两设备因距离远无法互相侦听,可能同时发送数据导致碰撞。RTS/CTS 机制 通过通知附近设备解决此问题。IFS 由于无线信道的可靠程度不如有线网络,所以 802.11 标准使用 停等方案 ,即站点每通过无线局域网发送完一帧,就要在收到对方的确认帧后才能继续发送下一帧。
为了尽量避免冲突,802.11 标准规定,所有站完成发送后,必须等待一段很短的时间(继续监听)才能发送下一帧。这段时间称为帧间间隔(InterFrame Space,IFS)。帧间间隔的长短取决于该站要发送的帧的类型,这些类型用于优先级管理,确保关键帧
802.11 标准使用了下列三种 IFS:
SIFS(Short IFS):当设备发送一个数据帧后,它会等待 SIFS 时间,以便快速发送另一个数据帧或发送 ACK(确认)帧作为响应。 DIFS(Distributed IFS):当设备想要发送数据时,它首先侦听信道,如果信道被其他设备占用,则等待一个 DIFS 的时间,然后再次侦听信道。 PIFS(Point Coordination IFS):中心协调器使用 PIFS 来在其他设备竞争前抢占信道。 NAV 在 CSMA/CA 中,网路分配向量(NAV)是用来告诉其他节点预计要占
用无线媒体多长时间的一种机制。
在发送 RTS(请求发送)和 CTS(清除发送)帧时,发送节点会
在帧头中包含一个持续时间字段,这个字段表示从发送当前帧到接收到最后一个 ACK 帧所需的时
间。
其他节点在收到 RTS 或 CTS 帧时,会根据帧中声明的 预计占用时间 ,在自己的 NAV 计时器上设定一个倒计时。
在 NAV 倒计时期间,设备会 认为信道被占用 ,即使它侦听到的无线信号很弱或根本没检测到数据,也不会尝试发送,以避免干扰正在通信的设备。
简单来说,NAV 就像设备内部的一个“占用表”,告诉自己:别人正在用,等一会再发。
3.5 - 局域网和广域网 了解局域网和广域网的协议字段,可能在选择题中考察。
局域网 局域网(Local Area Network,LAN)是一种覆盖范围较小、用于连接同一物理地点(如家庭、办公室、学校或企业内)的计算机和其他设备的计算机网络。
特性 局域网的特性主要由三个要素决定:拓扑结构 、传输介质 和 介质访问控制方式 ,其中介质访问控制方式是最关键的因素,它决定了局域网的主要技术特性。
常见的局域网 拓扑结构 主要包括以下四类:
星形结构 环形结构 总线形结构 星形与总线形结合的复合型结构 在 传输介质 方面,局域网可以采用铜缆、双绞线和光纤等多种介质,其中双绞线是当前的主流传输介质。
局域网常用的 介质访问控制方法 包括 CSMA/CD 协议、令牌总线协议和令牌环协议。
其中,CSMA/CD 协议和令牌总线协议主要应用于总线形局域网,而令牌环协议则主要用于环形局域网。
实现 局域网主要包含三种实现:
以太网(目前使用范围最广)。逻辑拓扑是总线形结构,物理拓扑是星形结构。 令牌环(Token Ring,IEEE802.5)。逻辑拓扑是环形结构,物理拓扑是星形结构。 FDDI(光纤分布数字接口,IEE802.8)。逻辑拓扑是环形结构,物理拓扑是双环结构。 以太网 在实际的局域网应用中,由于以太网占据垄断地位,所以基本上成为了局域网的代名词,
需要对局域网的概念有深入了解。
传输介质 以太网常用的传输介质有 4 种:粗缆、细缆、双绞线和光纤,这里需要熟练掌握它们的英文名,
常在选择题中出现:
参数 10BASE5 10BASE2 10BASE-T 10BASE-FL 传输媒体 粗缆 细缆 双绞线 光纤对 编码 曼彻斯特编码 曼彻斯特编码 曼彻斯特编码 曼彻斯特编码 拓扑结构 总线形 总线形 星形 点对点 网络适配器 早期以太网 早期以太网 现代以太网 现代以太网
注意上述传输介质的英文名称其实是挺有讲究的:
首先是前缀的数字,代表的是传输介质的速率,10 代表 10 Mbps,100 代表 100 Mbps,注意这里是 Mbps 而不是 MB/s。
其次是中间的 base 一次,代表基带传输(Baseband),基带与宽带(broadband)相对应。基带表示直接传输原始数字信号,不调制;宽带代表使用模拟调制技术传输多个频道信号,常见于有线电视等。
最后是后缀的英文字母,代表的传输介质的类型:
注意字母 T 是 twisted pair 的首字母,含义是双绞线 。 FL 是 Fiber optic 的缩写,含义是光纤 。帧格式 101010101010 ··· 101010101010
如上图所示,以太网帧格式从逻辑上可以分为物理层控制字段、帧首部、数据负载、差错校验字段这四个部分,每个字段的具体说明如下所示:
物理层控制字段前导码(Preamble):7B由 7 字节的交替的 1 和 0 位组成,用于同步接收方的时钟。 帧开始分隔符(Start of Frame Delimiter, SFD):1B 帧首部:固定为 14B 目的地址(Destination MAC Address):6B 源地址(Source MAC Address):6B 类型/长度字段(Type/Length):2B如果值大于或等于 0x0600(1536),则表示帧携带的数据的类型(例如 IPv4、IPv6、ARP 等)。 如果值小于或等于 0x05DC(1500),则表示数据字段的长度。 负载数据和填充(Data and Padding):范围为 46-1500B 携带帧的有效载荷,即要传输的数据。 如果数据少于 46 字节,则需要填充,确保数据字段的最小长度为 46 字节。 差错校验字段帧校验序列(Frame Check Sequence, FCS):4 字节:一个循环冗余校验(CRC)值,用于错误检测。接收方计算帧的 CRC,并与这个字段进行比较,以确定帧是否在传输过程中被损坏。 为什么 前导码 和 帧开始定界符 不包括在以太网帧的最小和最大大小计算中?
需要注意的是,Preamble 和 SFD 确实是以太网标准规定的格式的一部分,但它们属于 物理层 的内容,而非 数据链路层 中的以太网帧内容。
以太网分为 物理层 和 数据链路层 。物理层负责比特级的传输和同步,而数据链路层负责处理数据的封装、地址标识和错误检测。
以太网帧的最大和最小大小为多少?
以太网帧的最小和最大大小(不包括前导码和帧开始定界符)有明确的规定,目的是确保帧的有效性并避免冲突。
其中最小大小为 64B,最大大小为 1518B。
最小帧大小的要求是为了确保冲突检测机制(如 CSMA/CD)能够正常工作。
最大帧大小也称为 标准帧 或 最大传输单元(MTU),它限制了每个帧可以承载的数据量,以确保设备处理负载不会过大。
以太网帧数据部分的最小大小为 46B,最大大小为 1500B。
以太网快速填充
无线局域网 帧格式 802.11 帧共有三种类型,即数据帧、控制帧和管理帧。数据帧的格式如图 3.28 所示。
802.11 数据帧由以下三部分组成:
MAC 首部,共 30 字节。帧的复杂性都在 MAC 首部。 帧主体,即帧的数据部分,不超过 2312 字节。 帧检验序列 FCS 是 MAC 尾部,共 4 字节。 可以观察到,802.11 帧首部中字段很多,但是其实主要考察的就是个别字段。
其中最重要的是 4 个地址字段(都是 MAC 地址)。这里仅讨论前三个地址(地址 4 用于自组网络)。
这三个地址的内容取决于帧控制字段中的“去往 AP”和“来自 AP”这两个字段的数值,如下表所示:
去往 AP 来自 AP 地址 1 地址 2 地址 3 地址 4 0 1 接收地址 = 目的地址 发送地址 = AP 地址 源地址 —— 1 0 接收地址 = AP 地址 发送地址 = 源地址 目的地址 ——
💡核心记忆点:
地址 1:谁接收这帧(无线信号的接收者) 地址 2:谁发的这帧(无线信号的发送者) 地址 3:通信的最终目标或源(真实的目的地或来源) VLAN VLAN(Virtual Local Area Network)虚拟局域网,是通过逻辑划分的方式,把一个物理局域网拆分成多个独立的子网。
打个比方:一家公司只有一个办公室(一个交换机),但希望让财务部、技术部和人事部各自的数据隔离,互不干扰。VLAN 就像是在这一个办公室里,用“看不见的墙”把它们隔开,互相听不到对方说话。
⚙️ 那么 VLAN 是如何实现的呢?
VLAN 是通过 交换机 和 VLAN 标签(Tag)实现的。简单来说:
普通交换机:看网线在哪个口(port)来转发数据。 支持 VLAN 的交换机:会在数据包中加上 VLAN 标签,按“部门”来转发。 802.3c 标准定义了支持 VLAN 的以太网帧格式的扩展。它在以太网帧中插入一个 4 字节的
标识符(插在源地址字段和类型字段之间),称为 VLAN 标签,用来指明发送该帧的计算机属于
哪个虚拟局域网。插入 VLAN 标签的帧称为 802.1Q 帧,如下图所示。
其中 VID(VLAN ID)为 12 位,一个 VLAN 交换机最多支持 4096 个 VLAN。
📦 VLAN 示例:
假设有三台电脑:
PC1:财务部,接在 VLAN 10 PC2:技术部,接在 VLAN 20 PC3:人事部,接在 VLAN 30 它们都连在一台交换机上,如果没有 VLAN,三者可以互相通信。如果配置了 VLAN:
PC1 发的广播,只有 VLAN 10 内的设备能收到。 PC2 和 PC3 不会收到 PC1 的数据,除非通过路由器(或者三层交换机)跨 VLAN 通信。 广域网 HDLC 协议 HDLC(High-Level Data Link Control,高级数据链路控制)是一种 面向比特(bit-oriented) 的 数据链路层协议,用于在点对点或点对多点通信中提供可靠的数据传输。
HDLC 几个特点可以被简单总结为:面向比特、面向连接、提供可靠传输。
需要注意的是 HDLC 使用 零比特填充法 来组帧。
PPP 协议 PPP(Point-to-Point Protocol)是一种数据链路层协议,用于在两个点对点连接的网络之间传输数据。PPP 最初是为拨号连接设计的,但它后来被广泛用于建立各种类型的点对点连接,包括 DSL(数字用户线路)、ISDN(综合业务数字网)和串口连接等。
3.6 - 数据链路层设备 掌握网桥和交换机的工作原理和功能,可能在选择题中考察,也会大题中作为知识点进行考察。
交换机 交换机(Switch)是网络中用于连接设备并转发数据帧的二层设备。它通过分析数据帧中的 MAC 地址,将数据帧从接收端口精准转发到目标设备所在的端口。相比集线器 ,交换机只将数据帧发送到必要端口,避免广播到整个网络,显著降低碰撞域,提升带宽利用率和传输速度。
转发表 转发表(也称 MAC 地址表)是交换机内部维护的一张记录表,存储了网络设备 MAC 地址与其连接端口的对应关系。每条记录通常包含以下信息:
MAC 地址 :网络设备的唯一标识。端口号 :设备连接的交换机端口。附加信息 (可选):如 VLAN 标识或条目有效时间。如上图所示,交换机 A 和 B 分别通过转发表记录了通往每个 MAC 地址的端口。
转发流程 交换机收到数据帧后,会根据转发表执行以下步骤:
检查目标 MAC 地址 :从数据帧中提取目标 MAC 地址。查询转发表 :如果转发表中存在目标 MAC 地址的记录,交换机将数据帧直接转发到对应端口。 如果转发表中没有目标 MAC 地址,交换机将数据帧广播到除接收端口外的所有端口(称为广播帧),以寻找目标设备。 转发数据帧 :根据查询结果,数据帧被发送到目标端口或广播。交换方式 交换机的交换方式决定了 交换机在接收到数据帧后,决定如何以及何时将该帧转发到目标端口,交换方式有如下三种:
直通交换 存储转发 碎片隔离:介于直通交换和存储转发之间,检查数据帧的前64字节(以太网最小帧长),若帧长不足64字节(碎片),则丢弃;若正常,则转发。 网桥 网桥(Bridge)的功能和交换机基本一致,两者都是二层网络设备,用于转发数据帧。网桥中也有转发表的概念,转发过程和交换机一致,这里不再赘述。
那么 网桥和交换机区别
网桥是比较早期计算机网络使用的设备,现在已经渐渐被交换机替代,两者的重要区别如下表:
方面 网桥(Bridge) 交换机(Switch) 端口数量 通常较少(2~4 个) 通常很多(几十个甚至上百个) 性能 软件转发,处理能力较弱 硬件转发(ASIC 芯片),转发速度更快 功能 简单地转发帧,适合小型或实验网络 支持 VLAN、端口镜像、链路聚合等高级功能 使用场景 用于连接两个小型网络 用于构建现代企业内部网络(LAN)
4 - 网络层 本章是计算机网络中的重点,会在选择题中考察,其中知识点也会与其他知识结合,放在大题中考察,需要熟练掌握 IP 协议以及 IP 数据包从一台主机发送到另一台主机的逻辑过程。
学习思维导图:
# 网络层
## 网络层功能
- 异构网络互联
- 路由和转发
- SDN基本概念
- 拥塞控制
## 路由算法
- 静态路由和动态路由
- 距离-向量路由算法
- 链路状态路由算法
- 层次路由
## IPV4
- IPv4分组
- IPv4地址和NAT
- 子网划分、路由聚集、子网掩码和CIDR
- ARP, DHCP, ICMP协议
## IPv6
- IPv6主要特点
- IPv6地址
## 路由协议
- 自治系统
- 域内路由和域间路由
- RIP路由协议
- OSPF路由协议
- BGP路由协议
## IP组播
- 组播的概念
- IP组播地址
## 移动IP
- 移动IP的概念
- 移动IP通信过程
## 网络层设备
- 路由器的组成和功能
- 路由表与分组转发
网络层功能
路由选择:网络层负责确定数据包从源到目的地的最佳路径,以确保数据包能够跨越多个网络或子网。路由选择算法用于决定数据包应该通过哪些中间路由器传输,以达到目的地。 数据包转发:一旦确定了数据包的路径,网络层将数据包从一个路由器或交换机传递到下一个路由器或交换机,直到到达目的地。这个过程称为数据包转发。 寻址和标识:网络层使用 IP 地址来唯一标识主机和路由器。IP 地址是网络层的核心标识机制,它帮助路由器和交换机将数据包正确地传送到目的地。 分段和重组:网络层可以将数据流分成更小的数据包(分段),以便在网络上传输。在目的地,这些分段将被重新组装成原始数据流。 数据包的传输和传递:网络层通过控制数据包的传输和传递来确保数据的可靠性和完整性。这包括错误检测、丢包处理和数据包的重新发送。 4.1 - IP 网络层的重点内容,需熟练掌握 IPv4 地址的格式、分组、CIDR 以及 NAT 内容,会在选择题和大题中考察。除此外,掌握组播、IPv6 和移动 IP 的概念,可能在选择题中考察。
IP 协议初探 在真实世界中,我们使用地址找到一个地点,比如 中国 北京市 海淀区 某街道 某小区 某一栋 某一户。
在互联网中我们如果想定位某个机器,也需要使用同样的方式给其指定一个地址,这样的地址就叫做 IP 地址,IP 的英文全程是 Internet Protocol,直译作互联网协议。
但仅有地址是不够的,如何将数据从源地址发送到目的地址也是 IP 协议需要解决的一个问题。互联网是一个由众多网络设备组成的一个全球性的网络,从 一个机器 到 另一个机器,中间可能需要经过多个的网络设备,如何保证我们的数据可以 通过某条路径到达 正确地目的地呢,这个过程需要 IP 协议和协议共同配合以实现,在后面我们会逐步了解这个过程。
IP 协议目前包含两个版本,分别是 IPv4(Version 4)以及 IPv6(Version 6),后文将逐步介绍这两个协议,当然重点在于掌握 IPv4 的具体细节。
IPv4 地址格式 IPv4 的地址由 4 个字节构成,共有 32 位,比如 11000000.10101000.00000100.00000010 就是一个 IPv4 的地址。
点分十进制 IPv4 地址的二进制表示较为复杂,因此通常采用点分十进制表示法。
在点分十进制中,每个字节的值用十进制数表示 ,字节之间以点号分隔,因此得名点分十进制。
上述 IPv4 地址 11000000.10101000.00000100.00000010 的点分十进制形式为 192.168.4.2。
网络和主机地址 前文已经谈到,IP 地址是帮助我们在互联网中定位到一个机器,从而可以根据该地址进行数据传输。
所以,从逻辑上来说,IP 地址可以被拆分为两个部分:
网络编号 :IP 地址的前若干位,以确定一个网络。主机编号 :IP 地址的后若干位,以在网络中确定的一个机器。网络编号确定 IP 地址在哪个网络中,主机编号确定该机器是网络中的哪一台机器。
IPv4 首部 IP 协议位于 OSI 7 层模型的网络层,其承载上层(传输层)的数据,对其进行 封装 ,然后传递给下层(数据链路层)进行进一步的处理。
封装的具体过程就是为 传输层的数据 加上 IP 协议的首部的二进制表示,IPv4 的首部的 逻辑格式 如下图所示,其中包含多个字段,长度通常为 20 个字节。
这一小节我会简单介绍各个字段,帮助大家建立一个粗略的了解,部分字段的细节我会在后面几个小节详解说明。
版本(Version):4 位字段,用于指定 IP 协议版本,IPv4 的版本为 4。 头部长度(Header Length):4 位字段,用于指示 IPv4 首部的长度,以 4 字节为单位。由于 IPv4 首部的固定部分长度为 20 字节,因此这个字段的值通常是 5(即该字段二进制表示为 0101,5 * 4(4 字节为单位) = 20,最终表示的长度为 20)。 服务类型(Type of Service):8 位字段,用于指定数据报的服务质量(Quality of Service,QoS),包括优先级、延迟、吞吐量等。 总长度(Total Length):16 位字段,指定整个 IPv4 数据报(包括首部和数据部分)的总长度,以字节为单位。最大值为 65535 字节。 标识(Identification):16 位字段,用于唯一标识数据报。通常在数据报分片时用于重新组装数据报。 标志(Flags):3 位字段,包括以下标志:最左边位:保留为 0,未使用。 DF(Don’t Fragment):如果设置为 1,表示数据报不允许分片。则路由器会丢弃该数据报,并发送一个 ICMP 错误消息(“Fragmentation Needed and DF Set”)返回给发送方,告知需要分片但不允许分片。 如果设置为 0,标识允许分片,路由器在传输过程中如果需要,可以将数据报分片,以确保数据报能够通过传输链路。 MF(More Fragments):如果设置为 1,还有更多的分片; 如果设置为 0,表示当前分片是对应数据报的最后一个分片,或者表示当前数据报根本没有分片。 片偏移(Fragment Offset):13 位字段,用于指示数据报分片的位置。以 8 字节为单位,表示相对于原始数据报的偏移量。 生存时间(Time to Live,TTL):8 位字段,指定数据报在网络中可存在的最大时间(跳数),每经过一个路由器,TTL 减 1,当 TTL 减至 0 时,数据报被丢弃。 协议(Protocol):8 位字段,指定上层协议,表示数据报的载荷是由哪个协议处理。例如,6 表示 TCP,17 表示 UDP。 首部校验和(Header Checksum): 源 IP 地址(Source IP Address): 目标 IP 地址(Destination IP Address): 选项(Options):可选字段,长度可变,用于包含一些额外的信息。IPv4 首部中的选项字段通常很少被使用。 分片和相关字段 简而言之,
IP 数据报的最大长度为 65535 字节(总长度字段为 16 位,16 位可以表示的最大非负整数为 65535),而数据链路层的 MTU 往往都小于该值(比如以太网 ethernet 的 MTU 为 1500),所以为了在数据链路上传输这些数据,就需要将数据报(ip packet)进行拆分为不同的分片(ip fragmentation),更多关于分片的细节可以查看 IP 数据报分片 。
这个时候就会出现两个问题,我将 packet A 和 packet B 都拆分为了不同分片,比如我将 packet A 拆分为分片 A1、A2 和 A3,将 packet B 拆分 B1、B2。那么我如何区分这些不同的分片,我怎么知道 A1 是来自于 packet A 而不是 packet B 的呢?以及我如何将同一个数据报的不同分片再结合起来形成原始数据报呢?
为了实现以上需求,IP 协议首部包含如下字段:
Identification 标识字段用于区分 不同数据报 以及其 分片 Fragment Offset 标识字段标识当前分片中的数据在整个数据报中的偏移 差错校验字段 IP 首部的 checksum 为 IP 协议的差错校验字段,用于检验 IP 首部在传输的过程中是否发生错误,接下来我会告诉你如何通过该字段进行校验。
当一个 IP 数据报被创建时,发送端设备会计算 IP 头部的校验和,并填充 IP 数据报中的 checksum 字段。
当 路由器 和 目标机器 在收到数据报时会重新计算首部校验和,并将计算得到的校验和和接收到的 IP 数据报中的 checksum 进行比较。如果不一致的话,则说明 IP 数据报中的某些数据在传输的过程中出现变动,就需要丢弃该 IP 数据报。
需要注意的是,当 IP 数据报 经过某个路由器时,路由器需要重新计算并填充 checksum 字段,因为 IP 数据报中的某些字段在经过路由器时会被改变(比如 TLL 会减 1 等)。
一般而言,对于校验和,了解到以上程度即可,如果你好奇校验和究竟是如何计算且学有余力的话,可以查看 checksum 校验和计算方式 。
TTL TTL(Time To Live)用于控制 IP 分组的生命周期,发送方在发送 IP 分组时会设定一个 TTL 值,这个值是不固定的,但是一般是 32、64、128 或 255 这四个值中的一个。
当 IP 分组经过路由器时,路由器会自动 IP 分组中的 TTL 值减 1,路由器发现其 TTL = 0,则路由器会丢弃该 IP 分组,并且返回一个 ICMP “Time Exceed” 消息。
TTL = 6 TTL = 5 TTL = 4 TTL = 3 TTL = 2 TTL = 1 TTL = 0 IP 分组被丢弃 IPv4 分类寻址 在互联网早期,IP 地址采用了分类寻址(Classful Addressing),具体而言,就是将 IP 地址根据其网络编号(前几位)分为 A、B、C 和 D 类。
在分类寻址中,如果给定一个 IP 地址,我们可以马上判断出该 IP 地址属于哪一类网络(根据前几位的值),以及该 IP 地址的 网络编号 和 主机编号是多少。
类别 网络编号 主机数量 用途 网络数量 A 类 8 位,第一位一定是 1 $2^{24} - 2 = 16,777,214$ 大型网络 $2^7 = 128$ B 类 16 位,前两位一定是 10 $2^{16} - 2 = 65,534$ 中型规模网络 $2^{14}$ C 类 24 位,前三位一定是 110 $2^8 - 2 = 254$ 小型网络 $2^{21}$ D 类 4 位,固定为 1110 $2^{28} = 268,435,456$ 多播网络 $1$
分类寻址曾是 IP 协议设计的核心思路,旨在简化路由器设计和 IP 地址分配。这种简单策略在早期互联网中确实高效,很好地满足了当时的需求。然而,设计者未曾料到,短短几十年后,联网设备数量会爆炸式增长,每台设备都需要一个唯一的 IP 地址。IPv4 的 32 位地址空间(约 43 亿个地址)在全球设备激增的背景下,很快显得捉襟见肘。
分类 IP 这种“一刀切”的分配方式加剧了 IPv4 地址短缺的问题,这种分类方式过于不灵活,会造成地址空间浪费的现象。
例如,一个 B 类地址可以容纳 65,534 个主机,但如果一个组织只有几千台主机,剩余的地址就浪费了。同样,如果一个 C 类地址不足以满足一个组织的需求,但 B 类又太大,分配就变得困难。
为了解决这个问题,聪明的计算机专家们又发明了 CIDR、NAT 等技术 以及 IPv6 协议。
CIDR 无类别域间路由(CIDR,classless inter-domain routing)的主要目标是克服传统的基于类别的 IP 地址划分方法,使网络资源的分配更加灵活和高效。
在 分类寻址 中,每一类网络的网络编号的长度是固定的,在 CIDR 中,网络编号的长度是动态的,可以根据需求定制。其中网络编号的长度叫做前缀长度(Prefix Length),前缀长度通常以 IP 地址 斜杠后跟一个数字表示,例如,192.168.1.13/24 表示前 24 位是网络部分,剩下的位数用于主机。
子网掩码 这里就要提到子网掩码(subnet mask)这个概念,如果一个 CIDR 网络的前缀长度是 n 位的话,那么其子网掩码的二进制表示就是 111 (n 个 1) ... 0000 (32-n 个 0),该子网掩码对应的点分十进制如下图所示。
子网掩码的作用是找到 IP 地址的子网地址,IP 地址 与 子网掩码 进行 与操作计算 即可得到对应的子网地址。子网地址的主机位全部为 0。
子网划分 子网划分(Subnetting)是将一个较大的 IP 网络分割为多个更小的网络(子网)的过程。这种操作通常是在 IP 地址的网络部分与主机部分之间进一步引入子网位,以创建子网标识符。通过子网划分,网络管理员可以更有效地管理 IP 地址,减少网络流量,优化路由,并提高网络安全性。
在子网划分过程中,子网掩码(Subnet Mask)用于区分 IP 地址的网络部分和主机部分。常见的做法是通过调整子网掩码的长度,将更多位分配给网络部分,减少主机部分的位数。
子网划分包含 变长子网划分(Variable Length Subnet Masking, VLSM)和 固定长度子网划分(Fixed Length Subnet Mask, FLSM)两种方式。
变长子网划分 变长子网划分使用不同长度的掩码来划分 IP 地址空间,从而根据实际需求为各个子网分配不同数量的地址。
假设你有一个 C 类网络192.168.1.0/24,需要划分给三个部门,其中 A 部门需要 100 个 IP 地址,B 部门需要 50 个 IP 地址,C 部门只需要 25 个 IP 地址。
使用 VLSM,你可能会这样划分:
部分名称 子网地址 掩码 地址个数 A 部门 192.168.1.0/25255.255.255.128128 B 部门 192.168.1.128/26255.255.255.19264 C 部门 192.168.1.192/27255.255.255.22432
定长子网划分 固定长度子网划分使用相同长度的子网掩码来划分网络。这种方法在划分时更为简单和直接,但通常不如 VLSM 灵活高效。
假设你有一个 C 类网络192.168.1.0/24,需要划分给 A, B, C, D 四个部门,可以这样划分:
部分名称 子网地址 掩码 地址个数 A 部门 192.168.1.0/26255.255.255.19264 B 部门 192.168.1.64/26255.255.255.19264 C 部门 192.168.1.128/26255.255.255.19264 D 部门 192.168.1.192/26255.255.255.19264
注意以上地址个数中包含全 0 和全 1 的无效地址。
IP 数据报分片 P 数据报分片是一种网络通信中的过程,它允许较大的 IP 数据报在经过一些网络链路时被分割成多个较小的片段,以适应网络链路的最大传输单元(MTU,Maximum Transmission Unit)。MTU 是指网络链路能够传输的最大数据报大小,不同网络链路的 MTU 大小可能不同。当一个 IP 数据报的大小超过了某个链路的 MTU 时,它就需要被分片,以确保可以顺利传输。
MTU 指的是链路层帧中有效负载(Payload)部分的最大字节数,不包括链路层的帧头(Frame Header)和帧尾(Trailer)。
数据链路中的负载(Payload)包含 IP 数据报的首部(20B)和数据部分。
以下是 IP 数据报分片的基本过程:
发送端分片:发送端的主机首先创建一个 IP 数据报,并将它发送到目标主机。这个数据报的大小可能大于某些链路的 MTU。 路由器检查 MTU:当数据报经过路由器时,路由器会检查下一个链路的 MTU 大小。它会比较数据报的大小和链路 MTU。 如果数据报的大小小于或等于链路 MTU,那么数据报会继续传输,无需分片。 如果数据报的大小大于链路 MTU,那么路由器需要将数据报分片为多个较小的片段,以适应链路 MTU。 数据报分片:当数据报需要分片时,路由器会将数据报拆分成多个片段。每个片段都会包含原始数据报的一部分数据。 每个片段的头部将保留原始数据报的首部,但有一个特殊的标志(Fragment Offset)来指示它在原始数据报中的位置。 路由器将这些片段分别发送到下一个链路。 目标端重组:当片段到达目标主机时,目标主机将重新组装这些片段以恢复原始的数据报。 目标主机使用每个片段的标志和偏移量信息来确定如何正确地重组数据报。 分片例子:
MTU = 65335 MTU = 4000 MTU = 2500 Source Final destination Host Links Router MTU: Maximium Transmission Unit (Byte) Legend ID Offset More fragment flag Payload (byte) 578 0 0 10000 578 0 1 3976 578 497 1 3976 578 994 0 2048 578 0 1 2480 578 310 1 1496 578 1 2480 578 807 1 1496 578 994 0 2048 First fragmentation R1:(4000) First fragmentation R2:(2500) Part of IPv4 header (20 byte) The original packet R1 R2 497 以上图为例,假设我们有一个 IP 数据报,其总长度为 10000 字节,它需要通过两个链路,两个链路的 MTU 分别为 4000 和 2500 字节。当 IP 数据报经过第一个链路时,它需要被拆分为 3 个分片以通过链路:
数据报 首部长度 数据长度 总长度 偏移量 片偏移字段 MF 标志位 ID 字段 原始 IP 数据报 20 10000 10020 - 0 0 578 分片 1 20 3976 3996 0 0 1 578 分片 2 20 3976 3996 3976 497 1 578 分片 3 20 2048 2068 7952 994 0 578
分片后 IP 首部字段变化情况
所有分片中的 IP 数据报首部中的标识(ID,Identification)字段保持不变。
如果是最后一个分片,则 MF(More Fragment)标识位为 0,否则 MF 标识位为 1。
片偏移(offset)字段以 8 字节为单位,其值为 分片实际偏移量 / 8
分片后应该满足的条件
总长度 = 首部长度(20B) + 数据长度 ≤ MTU
数据长度必须为 8 的整数倍,因为 offset 字段以 8 字节为单位。
分片经过第二个链路时也会根据 MTU 进行拆分,以分片 1 为例进行说明:
数据报 首部长度 数据长度 总长度 实际偏移量 片偏移字段 MF 标志位 ID 字段 分片 1 20 3976 3996 0 0 1 578 分片 1.1 20 2480 2500 0 0 1 578 分片 1.2 20 1496 1516 2480 310 0 578
IP 组播 IP 组播(IP Multicast)是一种 IP 通信模式,允许一台发送器将数据报发送到多个接收器,而不是传统的单播(点对点通信)模式。组播是一种多对多的通信方式,非常适合用于广播、多媒体流传输和分布式应用中。
以下是 IP 组播的一些关键特点和概念:
组播组:IP 组播通信由一个或多个组播组组成,每个组都有一个唯一的组播组地址。组播组地址属于 IPv4 地址范围的特殊区域,通常以 224.0.0.0 到 239.255.255.255(D 类地址) 为范围。多个接收器可以订阅同一个组播组。 发送器:发送器是将数据报发送到组播组的设备。发送器只需发送一次数据报,然后由网络基础设施复制并传送给订阅了该组播组的接收器。 接收器:接收器是订阅了特定组播组的设备。它们希望接收组播组中的数据。接收器可以是单个主机、路由器或多个主机。 IGMP(Internet Group Management Protocol):IGMP 是用于管理 IP 组播成员的协议。它允许主机通知路由器它们希望加入或离开特定的组播组。路由器使用 IGMP 来了解哪些主机希望接收特定组播组的数据。 组播路由:组播路由器是网络中的设备,负责将组播数据报从发送器传送到接收器。组播路由器根据 IGMP 报文和组播组地址表,将数据报仅传送到订阅了该组播组的网络分支。 组播范围:IP 组播地址可以分为不同的范围,如永久组播地址、临时组播地址和本地链路组播地址,以满足不同的需求和使用情况。 Unicast Broadcast Multicast Class A,B,C
Class A,B,C... Hosts all 1's
Hosts all 1's... Class D
Class D... Text is not SVG - cannot display IPv6 IPv4 协议于 20 世纪 70 年代设计,经过互联网几十年的快速发展,至 2011 年 2 月,IPv4 地址已完全耗尽。为应对“IP 地址耗尽”问题,主要采取了以下三种措施:
采用无类别域间路由(CIDR):通过更灵活的地址分配方式,提高 IPv4 地址的使用效率。 使用网络地址转换(NAT):通过允许多个设备共享同一公网 IP 地址,有效节省全球 IP 地址资源。 推广新一代 IPv6 协议:IPv6 拥有更大的地址空间,从根本上解决 IP 地址短缺问题。 前两种方法仅能延缓 IPv4 地址耗尽的进程,而只有 IPv6 的广泛应用才能彻底解决这一问题。
特点 扩展的地址空间:IPv6 大幅扩展了 IP 地址空间,使用 128 位地址,相对于 IPv4 的 32 位地址,IPv6 提供了约 340 亿亿亿亿($3.4 \times 10^{38}$)个可能的地址,解决了 IPv4 地址枯竭的问题。 简化的报头:IPv6 报头相对于 IPv4 报头更简化,减少了路由器处理数据报的开销,提高了路由性能。 自动地址配置:IPv6 支持自动地址配置,其中设备可以通过 Router Advertisement 消息获取自己的 IPv6 地址,减少了手动配置的需要。 移动性支持:IPv6 内置了对移动 IP(Mobile IP)的支持,使移动设备能够无缝地切换网络而无需更改 IP 地址。 改进的安全性:IPv6 在设计上包括了对 IPsec(IP Security)的支持,这增加了网络通信的安全性和隐私保护。 多播和任播:IPv6 对多播和任播提供了更强大的支持,使网络更加高效。 简化的头部处理:IPv6 取消了 IPv4 中的首部校验和,减少了路由器在处理数据报时的负担。 更好的 QoS 支持:IPv6 提供了更多的选项和字段来支持服务质量(Quality of Service) 首部 Source Address%3CmxGraphModel%3E%3Croot%3E%3CmxCell%20id%3D%220%22%2F%3E%3CmxCell%20id%3D%221%22%20parent%3D%220%22%2F%3E%3CmxCell%20id%3D%222%22%20value%3D%22Version%22%20style%3D%22rounded%3D0%3BwhiteSpace%3Dwrap%3Bhtml%3D1%3BfillColor%3D%23E8EFDB%3BstrokeColor%3Ddefault%3BfontSize%3D16%3B%22%20vertex%3D%221%22%20parent%3D%221%22%3E%3CmxGeometry%20x%3D%22560%22%20y%3D%2280%22%20width%3D%22120%22%20height%3D%2250%22%20as%3D%22geometry%22%2F%3E%3C%2FmxCell%3E%3C%2Froot%3E%3C%2FmxGraphModel%3E
IPv6 首部包含 8 个字段,总长度固定为 40 字节。字段如下:
版本(Version):表示协议版本,对于 IPv6,该字段值为 6。用于标识数据包的协议类型,确保接收端正确解析。 流量类别(Traffic Class):用于服务质量(QoS)管理,标记数据包的优先级或服务类型(如实时流量或低优先级流量)。 流标签(Flow Label):标识属于同一数据流的数据包,便于路由器进行特殊处理(如保持数据包顺序或优先级)。 有效载荷长度(Packet Length):表示 IPv6 数据包中除首部外的有效载荷长度(单位:字节),包括扩展首部和上层数据。 下一首部(Next Header):指明紧跟 IPv6 首部之后的首部类型(如 TCP、UDP 或扩展首部),类似于 IPv4 的“协议”字段。 跳数限制(Hop Limit):表示数据包在网络中可经过的最大跳数,每经过一个路由器减 1,若减至 0 则丢弃。 源地址(Source Address):标识数据包的发送方地址。 目标地址(Destination Address):标识数据包的目标接收方地址。 地址 IPv6 地址使用 128 位,通常以冒号分隔的 16 位十六进制数表示,例如:2001:0db8:85a3:0000:0000:8a2e:0370:7334。
IPv6 地址在表示时支持 缩写规则 以简化书写,具体如下:
省略前导零 :对于每个 16 位域(4 个十六进制字符),可以省略开头的零,但每个域必须至少保留一个数字。例如,地址 4BF5:0000:0000:BA5F:039A:000A:2176 可简化为 4BF5:0:0:BA5F:39A:A:2176。压缩连续全零域 :当地址中存在连续的多个全零域(即 0000:0000:…),可用双冒号(::)代替这些域,进一步压缩地址。但双冒号在一个地址中只能使用一次,因为全零域的个数需根据地址的总域数(8 个域)推算。例如,上述地址可进一步缩写为 4BF5::BA5F:39A:A:2176。通过这些规则,IPv6 地址的表示更加简洁紧凑。
IPv6 数据报按照目的地址可以分为如下类型:
单播地址(Unicast Address):用于将数据报从一个源节点传输到一个目标节点。 多播地址(Multicast Address):用于将数据报传输到一组目标节点,而不是单个节点。 任播地址(Anycast Address):用于将数据报传输到一组目标节点中的最近者(最接近的一个)。 过渡方案 IPv4 到 IPv6 的过渡是一个复杂的过程,因为两种协议不直接兼容。以下是两种主要的过渡方法:
双栈技术 :网络设备同时实现 IPv4 和 IPv6 两个协议栈,分别配置一个 IPv4 地址和一个 IPv6 地址,这样这台设备既能和 IPv4 网络通信,也能和 IPv6 网络通信。双协议栈主机使用 DNS 来获取目标主机使用的 IP 地址,根据其类型使用 IPv4 或 IPv6 进行通信。 隧道技术 :是指在 IPv6 数据报要进入 IPv4 网络时,把整个 IPv6 数据报封装成 IPv4 数据报的数据部分,使原来的 IPv6 数据报就好像在 IPv4 网络的隧道中传输。当 IPv4 数据报离开 IPv4 网络时,再将其数据部分交给主机的 IPv6 协议。移动 IP 移动 IP(Mobile IP)是一种网络协议,用于实现移动设备在不同网络之间切换时,仍能够保持连接并无缝通信。移动 IP 的主要目标是支持移动性,允许移动设备在移动时保持与互联网或企业网络的连接。
通信过程 :
移动节点在家庭网络中连接,并分配了家庭网络的永久 IP 地址,建立了通信会话。 当移动节点决定移动到外部网络时,它会通知家庭网络的移动 IP 服务节点,告知其即将离开。 家庭网络的移动 IP 服务节点会分配一个临时 IP 地址,并记录移动节点的当前位置。 移动节点连接到外部网络,使用临时 IP 地址与外部网络中的其他设备通信。 当其他设备要与移动节点通信时,数据报被发送到移动节点的临时 IP 地址,然后到达外部网络。 外部网络的移动 IP 服务节点接收到数据报后,将数据报转发到移动节点的临时 IP 地址。 移动节点接收到数据报后,可以回复或继续与外部网络中的其他设备通信。 如果移动节点决定返回家庭网络,它可以通知外部网络的移动 IP 服务节点,并断开与外部网络的连接。 移动节点返回家庭网络后,通信会话继续,并且移动节点将继续使用家庭网络的永久 IP 地址。 4.2 - ICMP 掌握 ICMP 的功能和应用,并且了解一下 ICMP 的消息类型,可能在选择题中考察。
ICMP(Internet Control Message Protocol)是一个网络层协议,用于在 IP 主机和路由器之间发送控制消息。ICMP 是 Internet 协议套件的一个重要组成部分,它主要用于诊断和报告网络中的错误和某些特定条件。
首部 类型 (Type) :8 位用于指定 ICMP 消息的类型。例如, Echo Request 的类型为 8 , Echo Reply 的类型为 0。 代码 (Code) :8 位为更进一步细分某个特定类型的 ICMP 消息而设置。例如,对于“目的地不可达”( Destination Unreachable )类型的消息,代码可以用来指定具体的不可达原因,如网络不可达、主机不可达等。 检验和 (Checksum) :16 位用于验证 ICMP 消息在传输过程中没有被损坏。这个检验和涵盖了整个 ICMP 消息。 其它字段这些字段的内容取决于 ICMP 消息的类型和代码。例如,对于 Echo Request 和 Echo Reply 消息,接下来的字段包括一个标识符( Identifier )和一个序列号( Sequence Number )。 消息类型 ICMP 的消息类型可以分为 差错报文 和 查询报文 这两大类型:
差错报文:用于报告网络通信过程中出现的各种错误。 查询报文:用于诊断或网络信息查询,主要用于网络测试和管理。 当然了,这里不需要背,了解消息类型的含义即可,比方说给你一个消息类型源点抑制,你能知道它是干嘛的就行。
差错报文 ICMP 的差错报文分为五大类型:
终点不可达(Destination Unreachable)当数据不能被传送到目的地时,发送此消息。 下面是一些常见的“不可达”子类型:Network Unreachable: 无法到达目标网络。Host Unreachable: 无法到达目标主机。Protocol Unreachable: 目标网络不支持所请求的协议。Port Unreachable: 目标主机上的特定端口不可用。Fragmentation Needed and Don't Fragment was Set: 数据包太大,需要分片,但数据包的“不分片”标志已设置。Source Route Failed: 源路由指定的路径失败。Network Unknown: 目标网络未知。Host Unknown: 目标主机未知。 源点抑制(Source Quench) 路由重定向(Redirect) 超时(Time Exceeded)当数据包在网络中传输的时间太长或超过了其 TTL (生存时间)时发送。有两种主要的子类型: TTL Exceeded in Transit: 数据包在传输过程中 TTL 达到零。Fragment Reassembly Time Exceeded: 分片重新组装超时。 参数错误(Parameter Problem )当 IP 头包含错误或不可识别的信息时,发送此消息。 查询报文 查询报文包含以下类型:
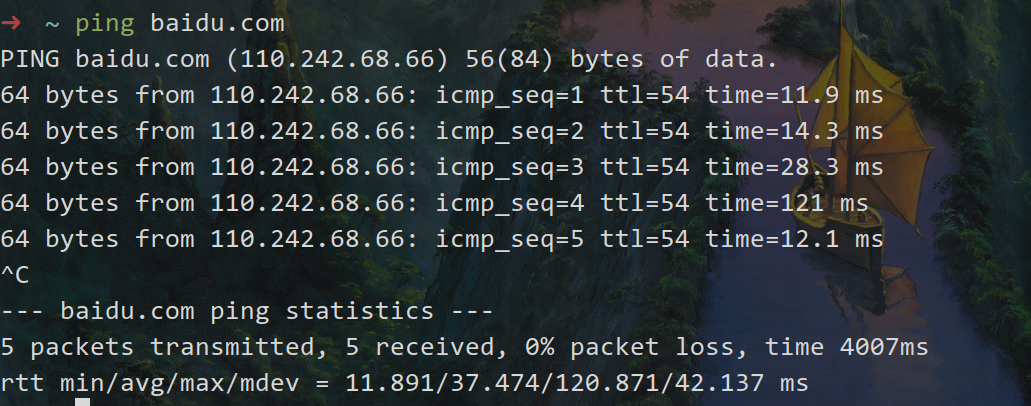
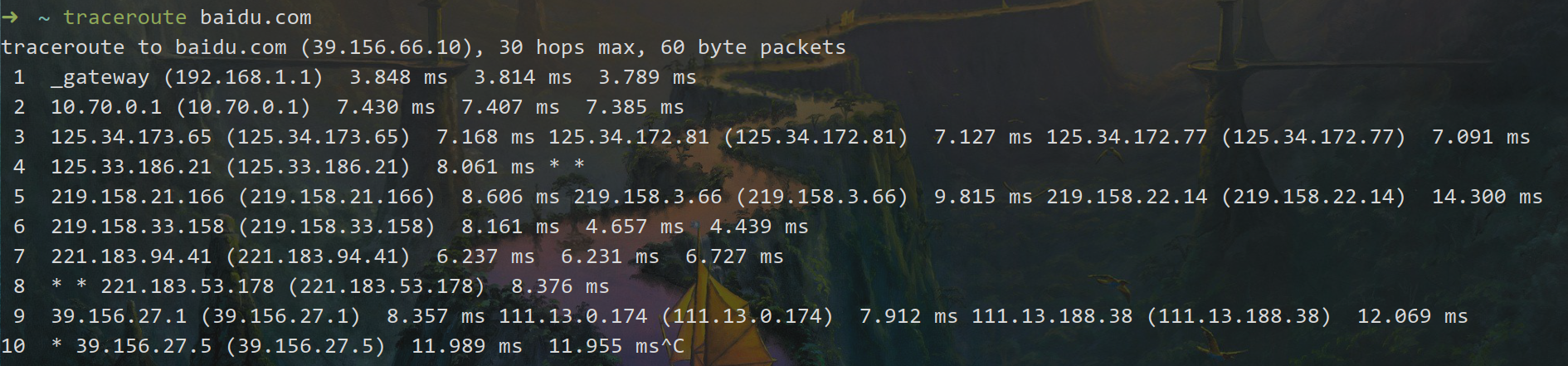
Echo Request 和 Echo Reply (ping)Echo Request: 通常被称为 ping 请求。用于测试目的地是否可达。Echo Reply: 通常被称为 ping 回应。是对 Echo Request 的回应。Timestamp Request and Timestamp ReplyAddress Mask Request and Address Mask Reply应用 这里需要了解基于 ICMP 协议的两个 linux 程序,一个是 ping,大家应该都比较熟悉。
另一个是 traceroute,用于寻找从起点到终点经过了哪些 IP 地址。
ping Ping 是一个简单的工具,用于测试两台主机之间的网络连接性,测量往返时延(RTT,Round-Trip Time),并检测是否有数据包丢失。
ping 利用了 ICMP 中的 Echo Request/Reply 消息类型:
发送 ICMP Echo Request:Ping 工具向目标主机发送一个 ICMP Echo Request 消息。 接收 ICMP Echo Reply:如果目标主机可达且未被防火墙阻止,它会回复一个 ICMP Echo Reply 消息。 计算时延:Ping 记录发送和接收消息的时间差,计算 RTT。 统计丢包:通过发送多个 Echo Request,统计有多少消息未收到回复,计算丢包率。 traceroute Traceroute 用于跟踪数据包从源到目标的路径,显示沿途经过的路由器(跳点)及其延迟。
Traceroute 利用 ICMP 的 Time Exceeded 消息和 IP 数据包的 TTL(Time To Live) 字段:
逐步增加 TTL:Traceroute 发送一系列 UDP 数据包(或 ICMP Echo Request,取决于实现),从 TTL=1 开始,每次递增 1。
每台路由器在转发数据包时将 TTL 减 1。当 TTL 减为 0 时,路由器丢弃数据包并返回一个 ICMP Time Exceeded 消息(类型 11,代码 0)。 记录跳点:Traceroute 记录发送 Time Exceeded 消息的路由器 IP 地址和响应时间。 重复此过程,直到数据包到达目标主机(目标返回 ICMP Echo Reply 或 UDP 端口不可达消息)。 显示路径:Traceroute 将每跳的路由器 IP 和延迟显示出来,构成从源到目标的完整路径。 4.3 - DHCP 掌握 DHCP 的功能和流程,可能在选择题中考察。
动态主机配置协议(DHCP)是一个网络管理协议,用于自动分配 IP 地址和其他网络配置参数给网络设备,从而允许它们连接到 IP 网络。
当你连接到一个网络中时,不管是通过无线网,还是在电脑上连接了以太网线,你会发现无需任何配置,你自动获取了一个 IP 地址,并可以通过该 IP 地址进行网络通信。
DHCP DISCOVER (broadcast)
DHCP DISCOVER (broadcast) DHCP Offer DHCP REQUEST DHCP ACK Where is the DHCP server ?
Where is the DHC... Hello, I need... DHCP server is
DHCP server is... Here is your... Text is not SVG - cannot display DHCP 的工作流程通常包括以下四个步骤,这个过程也被称作 DORA 过程,即 Discover, Offer, Request, 和 Acknowledgment。
Discover 客户端通过网络广播一个 DHCP 发现消息(DHCP DISCOVER),请求可用的网络配置信息。因为客户端还没有分配到 IP 地址,所以这个消息的源 IP 地址是 0.0.0.0 ,目的 IP 地址是 255.255.255.255 。 Offer:网络上的 DHCP 服务器接收到 DHCP 发现消息后,会向客户端发送一个 DHCP 提供消息(DHCP OFFER)。这个消息包含了一个提供给客户端的 IP 地址和其他配置信息,如子网掩码、DNS 服务器地址和 IP 地址租用期。 Request:客户端可能会从多个 DHCP 服务器收到多个 DHCP OFFER 消息。客户端选择其中一个提议,并通过广播一个 DHCP 请求消息(DHCP REQUEST)来响应这个提议,通知网络中的所有 DHCP 服务器它接受了哪个 DHCP 服务器的提议。 Acknowledgment:提供所选 IP 地址的 DHCP 服务器收到 DHCP 请求消息后,会发送一个 DHCP 确认消息(DHCP ACK)给客户端,确认 IP 地址和配置信息的租约。如果由于某种原因导致该 IP 地址不再可用或者有其他问题,DHCP 服务器可能会发送一个 DHCP 否认消息(DHCP NAK)。 4.4 - ARP 掌握 ARP 的概念和流程,可能在选择题中考察。
概念 ARP(Address Resolution Protocol,地址解析协议)是一种在 TCP/IP 网络中使用的协议,用于将 IP 地址转换为物理硬件地址(例如,MAC 地址)。ARP 的主要目的是确定要通过网络传输数据的目标设备的物理硬件地址,以便将数据帧正确地传送到目标设备。
10.1.1.2 Switch 10.1.1.5 10.1.1.4 10.1.1.3 Requesting the mac address for 10.1.1.1
Requesting the mac addr... Sending mac address
Sending mac address... Text is not SVG - cannot display 流程 以上图为例,主机 10.1.1.2 用 ARP 协议查找主机 10.1.1.4 的 MAC 地址,其流程如下图所示
sequenceDiagram
participant 10.1.1.2;
participant Switch;
10.1.1.2 ->> Switch: 请求 IP 地址为 10.1.1.4 的设备的 MAC 地址;
Switch ->> 10.1.1.3: 广播 ARP 请求;
Switch ->> 10.1.1.4: 广播 ARP 请求;
Switch ->> 10.1.1.5: 广播 ARP 请求;
10.1.1.4 ->> Switch: 返回 ARP 响应;
Switch ->> 10.1.1.2: 交换器转发 ARP 响应; 具体而言,一次 ARP 请求可以被拆分为如下步骤:
ARP 请求 当一台设备(我们称它为主机 A)需要发送数据包到同一局域网内的另一台设备(主机 B),但它只知道目标设备的 IP 地址时,它会在本地网络上广播一个 ARP 请求。这个请求的语义大致是这样的:“我拥有 IP 地址 X.X.X.X 的设备,请告诉我你的物理 MAC 地址。”
ARP 请求的目的 MAC 地址为 ff-ff-ff-ff-ff-ff-ff-ff,源 MAC 设置为自己的 MAC 地址。
网络上的广播 ARP 请求是一个广播帧,它发送到本地网络上的所有设备。每一台设备都会收到这个请求,但只有 IP 地址匹配请求中 IP 地址的设备会回应这个请求。
ARP 响应 当主机 B 收到这个 ARP 请求后,它会识别出请求中的 IP 地址与自己的 IP 地址相匹配,然后向主机 A 发送一个 ARP 响应。这个响应包含了主机 B 的 MAC 地址,并且这个响应是直接发送给主机 A 的,不是广播。
更新 ARP 缓存 主机 A 收到 ARP 响应后,它会在自己的 ARP 缓存表中更新这个信息,将主机 B 的 IP 地址与其 MAC 地址关联起来。ARP 缓存表中的这些条目通常会在一段时间后过期,所以可能需要定期更新。
数据传输 主机 A 现在知道了主机 B 的 MAC 地址,它可以构建一个以太网帧,将数据包含在其中,并使用 B 的 MAC 地址作为目的地址发送出去。
ARP 缓存 所有主机都会维护一个 ARP 缓存,该缓存存储了网络上其他设备的 IP 地址和 MAC 地址的映射。
这减少了广播 ARP 请求的需要,因为主机可以查看自己的缓存来找到之前解析过的地址。
以下是一个简化的 ARP 缓存表格示例,展示了 IP 地址与 MAC 地址的映射关系:
IP 地址 MAC 地址 状态 接口 192.168.1.1 00:1A:2B:3C:4D:5E 动态 eth0 192.168.1.2 00:1A:2B:3C:4D:5F 静态 eth0 192.168.1.3 00:1A:2B:3C:4D:60 动态 wlan0 192.168.1.4 00:1A:2B:3C:4D:61 动态 eth0
ARP 运行在哪一层
地址解析协议(ARP)实际上是一个介于数据链路层(第二层)和网络层(第三层)之间的协议。ARP 的功能是将网络层的地址(如 IPv4 地址)解析为数据链路层的地址(如以太网 MAC 地址)。虽然它处理的是网络层地址,但它运行在数据链路层,直接构建和发送数据链路层的帧。因此,它通常被认为是网络层的一个辅助协议,但技术上它操作在数据链路层。
4.5 - 路由算法 掌握 RIP 和 OSPF 的流程,可能在选择题中考察。
路由 这一节我们首先通过三个问题来认识什么是路由,接下来再在此基础上介绍路由协议。
什么是路由? 在一个 IP 网络中,数据包要从一个设备发送到另一个设备,中间通常需要经过多个路由器的转发。每个路由器就像是一个“交通指挥员”,决定数据包该往哪个方向走。
例如,PC-1(IP 地址为 192.168.1.5)通过如下图所示的网络向 PC-2(IP 地址为 10.1.1.5)发送数据包。当路由器 R1 接收到这些数据包时,它必须知道如何到达目标子网 10.1.1.0/24,否则将丢弃这些数据包。
路由器 R2 知道如何到达 PC-2,因为它有一个接口位于子网 10.1.1.0/24,并在路由表中包含了一条直接连接路由。然而,默认情况下,路由器 R1 和 R3 不知道如何到达 10.1.1.0/24。网络管理员需要配置一条静态路由,或者 R2 必须自动告知 R1 和 R3,它们可以将目的地为 10.1.1.0/24 的数据包发送到 R2,这种方式叫做动态路由。
路由器怎么知道往哪里转发? 路由器内部有一个叫 路由表 的数据结构,里面记录了各种目的 IP 地址该怎么走。这个表告诉路由器:当收到一个 IP Packet 时,应该把包发给哪个下一跳(下一个路由器)。
路由表如何建立? 路由表主要包含两种建立方式:
静态路由 动态路由 两个路由表建立方式各自适用于不同的场景:
特点 静态路由 动态路由 配置方式 手动配置 自动学习和适应 适用性 适用于小型网络或需要特定路由策略的情况 适用于大型、复杂的网络 稳定性 较稳定 可能更灵活,但较复杂 自动故障恢复 不支持自动故障恢复 支持自动故障检测和恢复 网络变化响应速度 静态,不会自动适应网络变化 自动适应网络变化,响应速度较快 管理复杂性 相对简单 较复杂,需要更多计算和资源 适用情况 较小规模的网络,特定路由策略需求 大型、复杂网络,需要动态适应
路由协议 路由协议是一种 用于路由器之间交换网络路由信息的通信规则 。它的主要作用是让路由器能够自动学习和维护到达各个目的网络的路径,从而实现数据包的正确转发。
路由协议的主要作用有两个:
自动学习路由 :当网络结构发生变化(如新增路由器、链路断开),路由协议能自动更新路由表,省去了手动配置的麻烦。选择最佳路径 :如果到同一个目标有多条路径,路由协议能根据跳数、带宽、延迟等因素计算出最优路径,提高网络效率。路由协议分为不同种类,各自适用于不同场景,在介绍其分类前,首先要理解计算机网络中自治系统的概念。
自治系统 一个 自治系统(AS,Autonomous System)是由一个或多个网络组成的集合,这些网络 在统一的管理和策略控制下运行 ,并对外表现为一个单一的路由实体。
互联网是由无数个独立组织维护的网络组成的。每个组织内部的网络结构和路由策略不同,AS 的概念让每个组织可以作为一个独立的“区域”,既能自主控制路由,又能通过标准协议与外部沟通,保证整个互联网正常运作。
AS 通常由一个 ISP(互联网服务提供商)、大型企业、大学等拥有和运营。AS 之间通过外部路由协议互联,组成整个互联网。
分类 路由协议根据其使用范围的不同,可以分为两大类:内部网关协议(IGP,Interior Gateway Protocol)和外部网关协议(EGP,Exterior Gateway Protocol)。
内部网关协议:在单个组织或自治系统(AS)内部使用的路由协议,常见的 IGP 协议包括 RIP 和 OSPF。这些协议的主要作用是在一个组织的网络内部传播和更新路由信息,以实现高效的网络通信。 外部网关协议:用于在不同组织或不同自治系统之间交换路由信息。如今,唯一广泛使用的 EGP 协议是 BGP。BGP 的设计初衷是为了控制跨组织网络之间的路由信息传递,从而实现自治系统之间的互联和路径控制。 对比 重点掌握 RIP、OSPF、BGP 三个协议的区别,三者的对比如下表所示:
项目 RIP OSPF BGP 封装协议 UDP IP TCP 传播方式 逐跳 泛洪 TCP 会话间传递 更新内容 全表,周期性 链路状态,事件驱动 路径属性,事件驱动 拓扑视图 无全局视图 拥有全图 无全图,仅路径属性 计算算法 Bellman-Ford Dijkstra 策略驱动 收敛速度 慢 快 慢(但更稳定) 带宽占用 高(周期发全表) 中(仅更新变化) 低(TCP 控制精细) 扩展性 差 较好 极强 应用场景 小型网络 企业内部网络 运营商/跨 AS 互联
RIP RIP(Routing Information Protocol,路由信息协议)是一种基于距离向量的路由协议,主要用于小型和中型网络中的内部网关协议。
距离向量 一个典型的距离向量(Distance Vector)可以表示为一个列表,其中每个条目包含以下信息:
目的地(To):目标网络或子网的地址。 跳数/度量值(Metric):从当前路由器到达目标网络的代价,通常以跳数、延迟、带宽等度量标准表示。 下一跳(Next Hop):到达目标网络的下一跳路由器的地址。 可以观察到,距离向量其实是和,下表是一个距离向量示例:
目标网络 跳数 下一跳 192.168.1.0/24 0 A 192.168.2.0/24 1 B 192.168.3.0/24 1 C
RIP 规定 最大跳数
此外,路由器将自己的距离向量广播给其他路由器时,距离向量中的下一跳是可以省略的,因为接收者默认认为所有距离向量中的下一跳就是发送该向量的那个路由器本身。
距离向量算法 在距离向量算法中,
通过 周期性地 与相邻路由器 交换距离向量信息 ,每个路由器能够逐渐获得整个网络的拓扑信息,并更新其路由表 以选择最佳路径 。
具体而言,工作流程如下:
初始化 :每个路由器初始化其距离向量,只包含自己直接连接的网络,距离设为 0。周期性更新 :每个路由器周期性地(30s)将其距离向量广播给所有相邻的路由器。接收和更新 :每个路由器接收到相邻路由器的距离向量后,检查是否有新的或更短的路径。如果有,则更新自己的距离向量和路由表。收敛 :经过多次交换和更新后,所有路由器的距离向量和路由表最终会收敛到最优路径。最短路径计算方法 当路由器 $A$ 接收到来自相邻路由器 $B$ 发送的关于某个子网 $N$ 的距离向量 $V_{B}$ 时,它需要将 $V_{B}$ 中的跳数加一 然后与当前的到达子网 $N$ 的距离向量 $V_{A}$ 进行比较(需要加一的原因时从 $A$ 出发要经过 $B$,所以多了一跳),具体比较方式如下:
如果 $A$ 不存在到达子网 $N$ 的路由的话,直接添加 $V_{B}$ 进入路由表 如果 $V_{B}$ 的跳数小于 $V_{A}$ 的跳数的话,使用 $V_{B}$ 替换 $V_{A}$ 以上过程使用的算法名称叫做 Bellman-Ford 算法,是一种寻找单源最短路径的算法,单源最短路径的意思是从一个结点出发到达其他结点的最短路径。这个算法不会直接考察,了解这个算法的名称即可。
RIP 坏消息传得慢 假设一个路由器检测到它无法到达一个网络,这个信息可能需要比较长的时间才能被网络中的所有路由器感知到,这也是 RIP 的一个缺点。
举例说明:
假设有路由器 A、B、C 连接成一条线:A---B---C。网络 X 连接到 C。
正常情况:A 知道通过 B 和 C 到达 X,跳数为 2。 C 和 X 之间的连接断开:C 检测到 X 不可达。 B 仍然会周期性地告诉 A,它可以通过 B 到达 X(因为 B 还不知道 C 和 X 之间的连接断开)。 A 收到 B 的更新后,会更新自己的路由表,认为通过 B 到达 X 的距离变大(可能是通过其他路径,或者仍然通过 B,但距离变为无穷大之前的某个值)。 这个过程会重复多次,直到 A 最终确定 X 不可达。 OSPF OSPF(Open Shortest Path First)是一种基于链路状态的内部网关协议(IGP),广泛应用于中大型网络中。
链路状态 路由器通过链路状态通告(LSA,Link State Advertisement)来了解其与邻居之间的链路状态。
在 RIP 路由算法中,路由器会定期将自己的距离向量发送给相邻的路由器。在 OSPF 中,也有类似的概念,不过这里传送的不是距离向量,而是链路状态通告。
路由器将其自身的状态和与邻居的链路状态信息打包成 链路状态包 (LSP,Link State Packet),并在网络中 洪泛传播 (flooding)。
每个 LSA 专注于描述一种类型的链路状态或网络信息。一个 LSA 包含的信息通常是:
路由器与某一特定链路的连接状态(如 Router LSA)。 某个网络的状态和与其相连的路由器信息(如 Network LSA)。 区域间或外部路由信息(如 Summary LSA 和 AS External LSA)。 链路状态数据库 链路状态数据库(LSDB,Link State Database)是 OSPF 协议中的一个关键组件,它存储了网络中所有链路状态通告(LSA)。通过 LSDB,每个路由器可以构建整个网络的拓扑图,并使用 Dijkstra 算法计算最短路径树。
这里举个例子方便大家理解 LSDB 的概念。
假设我们有一个简单的网络拓扑,包含 4 个路由器(R1, R2, R3, R4)和几个网络网段(NetA, NetB, NetC)。
在链路状态算法收敛之后,某个路由器的 LSDB 可能是如下这种形式:
LSA 类型 LSA ID 路由器 ID 链路 ID 链路类型 路径成本 连接的路由器或网络 Router 1 R1 NetA 广播链路 10 R2 Router 1 R1 NetC 广播链路 5 Router 2 R2 NetA 广播链路 10 R1 Router 2 R2 NetB 广播链路 15 R4 Router 2 R2 R3 点对点链路 20 R3 Router 3 R3 R2 点对点链路 20 R2 Router 3 R3 R4 点对点链路 10 R4 Router 4 R4 NetB 广播链路 15 R2 Router 4 R4 R3 点对点链路 10 R3
链路状态路由算法 距离向量算法(如 RIP)中,每个路由器只维护到各个目的网络的距离(如跳数)和下一跳信息,周期性将整个路由表发送给直接相邻的路由器,依赖邻居的更新来调整自己的路由表,缺乏全局视角,容易形成路由环路,收敛速度较慢,并且存在坏消息传得慢的问题。
而链路状态算法(如 OSPF)则由每个路由器通过链路状态广播(LSA)将本地链路信息 泛洪 给全网,所有路由器据此构建一致的网络拓扑图,然后独立运行 Dijkstra 最短路径算法计算路由,具备 全局视角 ,收敛速度快,稳定性好,适合大型复杂网络。
下图通过一个实例对比了 距离向量 和 链路状态 算法的区别:
R1 到 1.1.1.1 的 metric 为 5
更新我到 1.1.1.1 的 metric 为 10
R2 到 1.1.1.1 的 metric 为 10
更新我到 1.1.1.1 的 metric 为 15
(2) Flood R1's update unchanged
R1 到 1.1.1.1 的 metric 为 5
(3) Process R1's update in the background
R1 到 1.1.1.1 的 metric 为 5
R1 通过 metric 为 5 的链路连接到 R2
更新我到 1.1.1.1 的 metric 为 15
BGP BGP(Border Gateway Protocol,边界网关协议)是互联网的核心路由协议,用于在不同 自治系统 之间交换路由信息,属于路径向量(Path Vector)协议,目前广泛使用的版本是 BGP-4。
在 BGP 中,自治系统(AS)是互联网的基本单位,每个 AS 是一个由单个组织控制的网络集合(如一个运营商或大型企业)。AS 与 AS 之间的路由交换就是通过 BGP 完成的,AS 之内的路由交换通过内部网关协议完成。
BGP 原理 (1) 选择 AS 发言人
每个 AS 内部可以有多个 BGP 路由器,但对外通常由一个或多个 “BGP 发言人” 代表整个 AS 与其他 AS 进行路由信息的交换。 (2) 路径向量信息的交换
BGP 发言人之间通过 TCP 连接建立 BGP 会话,并交换路由前缀及其路径属性。 每个 AS 在接收到路径信息后,可以根据自身策略决定:是否接受该路由 是否将其传播给其他邻居 是否作为本地的最佳路径使用 (3) 路由更新与维护机制
BGP 是 事件驱动协议 ,不像 RIP 周期性更新,而是在以下事件发生时才发送 UPDATE 消息:新的可达前缀出现 现有前缀的属性发生变化 某个前缀不再可达(发送 Withdraw 消息) 4.6 - SDN 了解 SDN 控制平面、数据平面、接口以及流表基本概念,可能在选择题中考察一题。
软件定义网络 (SDN) 是一种新颖的网络架构,它将网络的控制功能从传统的网络硬件中解耦出来,并允许通过软件应用程序来进行集中式管理。SDN 提供了更高的网络灵活性,使得网络配置、优化、管理和调试都变得更加简单。
控制平面和数据平面 在 SDN 中,主要有两个关键的组件:数据平面 (Data Plane) 和控制平面 (Control Plane)。
数据平面 (Data Plane):这是网络中负责处理数据包的部分,通常是在交换机、路由器等设备上。 它基于控制平面提供的策略和规则,进行数据包的转发、丢弃或修改。 数据平面通常需要高效地执行操作,因为它直接影响网络的性能。 控制平面 (Control Plane):控制平面负责整个网络的决策和策略,确定如何处理在网络中流动的数据包。 在传统的网络设备中,控制平面直接嵌入在设备上。但在 SDN 中,这个控制平面被抽象为一个集中的软件控制器。 控制器与网络设备之间的交互是通过某些标准化的接口进行的,这样可以确保多厂商设备的互操作性。 接口 SDN 架构中的接口主要分为南向接口和北向接口。
南向接口 (Southbound Interface):这是 SDN 控制器与网络设备之间的接口。 它允许控制器下发流表到数据平面设备,并从设备获取信息。 OpenFlow 是最常用的南向接口协议,但还有其他协议也被使用。 北向接口 (Northbound Interface):这是 SDN 控制器与网络应用或上层服务之间的接口。 通过这个接口,应用程序可以请求网络服务或查询网络状态,并指导控制器进行相应的网络配置。 这个接口通常没有严格的标准,但通常提供 RESTful API 供开发者使用。 除此之外,还有东向接口 (East/West Interface),它用于 SDN 控制器之间的通信,特别是在多控制器的环境中。
流表 流表基本上是一个数据库或查找表,用于决定如何处理经过交换机的数据包。
在 OpenFlow 交换机中,可能有多个流表,并且数据包可能按照顺序经过这些流表。每个流表可能基于不同的规则或策略来处理数据包,这为网络设计提供了高度的灵活性。
流表的内容通常由 SDN 控制器动态管理和更新,这是通过南向接口(如 OpenFlow 协议)实现的。当网络的状态或策略发生变化时,控制器可以修改流表条目以适应新的需求。
流表中主要包含如下部分:
匹配字段 (Match Fields):这些字段描述了特定的数据包特征。例如,它可以匹配数据包的源地址、目的地址、端口号、VLAN 标签等。 当一个数据包到达交换机时,它的头部字段会与流表中的匹配字段进行比较,以决定哪个条目适用于该数据包。 优先级 (Priority):当多个流表条目都能匹配到一个数据包时,优先级最高的条目会被选中。 优先级使得网络管理员可以设计更为精确和特定的流规则。 计数器 (Counters):这些是用于收集统计信息的,如匹配到某个流条目的数据包数量。 计数器有助于网络监控和分析。 指令和动作 (Instructions & Actions):当一个数据包与流表条目匹配时,会执行相应的指令和动作。 常见的动作包括:转发数据包到特定的端口、丢弃数据包、修改数据包头部信息、发送数据包到控制器等。 4.7 - 网络层设备 掌握路由器的组成和功能,以及掌握路由表的画法,会在选择题和大题中考察。
路由器 路由器(Router)是一种实现网络互连的设备,在 OSI 网络模型中的第三层,提供 路由 与 转发 的两种重要机制;可以决定数据包从来源端到目的端所经过的路由路径,这个过程称为路由;将路由器输入端的数据包移至适当路由器输出端,称为转发。
组成 简单来说,路由器主要由以下软硬件组成:
硬件:CPU:运行操作系统,处理路由协议。 交换结构:高速传输数据包,连接输入输出端口。 网络接口:以太网、光纤等,收发数据包。 软件:操作系统:运行专用的嵌入式操作系统,提供路由协议支持、配置管理等功能。 路由表 路由表是路由器内部的数据结构,其中包含了有关网络之间如何进行路由的信息。路由表是根据路由协议(如 RIP、OSPF、BGP 等)和手动配置动态生成和维护的。
路由表包含如下信息:
目标网络(Network Destination):表示数据包要传递到的目标网络或主机。 子网掩码(Network Mask):确定了目标网络的范围,路由器使用它来匹配数据包的目标地址。 网关(Gateway):数据报转接口的 IP 地址。 接口(Interface):指明了路由器上哪个物理或逻辑接口将被用来转发数据包。 跳数/度量值(Metric):跳数或度量值是路由选择的一个度量标准,用来表示到达目标地址的成本。如果存在多条路由到同一个目的地,路由器通常会选择跃点数最低的路由。 功能 路由表的核心功能就是路由决策和分组转发,接收数据包,查询路由表,然后从某个端口转发出去。
分组转发 分组转发是指路由器根据数据包的目的 IP 地址和其内部的路由表,决定将数据包发送到下一个网络节点(下一跳)或目标设备的过程。其详细工作流程如下:
接收和解析数据包 查询路由表:路由器将目的 IP 地址与路由表中的条目进行匹配,使用最长前缀匹配(Longest Prefix Match, LPM)算法选择最佳路由。 处理 TTL 和其他字段:路由器减少数据包的 TTL(Time To Live)值,防止循环转发。 如果需要,执行其他处理,如分片、重组或 NAT。 转发数据包根据路由表查找结果,将数据包发送到指定的下一跳地址或直接连接的设备。 路由表在分组转发的时候,需要修改 IP 数据包中的哪些字段?
TTL:TTL 减 1。 checksum:因为 IP 首部有字段被修改,所以校验和需要重新计算。 如果是 NAT 路由器的话,需要修改 源 IP 或者 目的 IP 地址。 如果 IP 数据包长度超过输出链路的 MTU,则总长度字段、标志字段、片偏移字段都需要修改。 最长前缀匹配 当路由器收到一个数据包时,它会提取数据包的目的 IP 地址,并与路由表中的条目进行比较。最长前缀匹配的核心是选择与目的 IP 地址前缀匹配最长的路由表项,因为更长的前缀表示更具体的路由,优先级更高。
举个实际例子,假设有如下路由表:
网络前缀 子网掩码 下一跳 192.168.1.0/24 255.255.255.0 接口 A 192.168.0.0/16 255.255.0.0 接口 B 0.0.0.0/0 0.0.0.0 接口 C
对于目的 IP 地址 192.168.1.100:
1. 与 192.168.1.0/24 匹配:前 24 位完全匹配。
2. 与 192.168.0.0/16 匹配:前 16 位匹配。
3. 与 0.0.0.0/0 匹配:默认路由,总是匹配。
由于 /24 是最长的前缀,路由器选择接口 A 作为下一跳。
NAT NAT(Network Address Translation,网络地址转换)用于将一个 IP 地址空间映射到另一个 IP 地址空间,通常用于解决 IPv4 地址不足的问题并提供一定的网络安全功能。NAT 的主要功能是将私有 IP 地址(例如局域网中的 192.168.x.x)转换为公网 IP 地址(或反之),以实现局域网设备与外部网络(如互联网)的通信。
Default Gateway
145.12.131.7
NAT 表 上图中路由器的 NAT 表 的示例如下:
私有 IP 地址 私有端口 公有 IP 地址 公有端口 协议 连接状态 192.168.100.3 12345 145.12.131.7 54321 TCP ESTABLISHED 192.168.100.4 8888 145.12.131.7 54322 UDP NEW 192.168.100.5 15839 145.12.131.7 54323 TCP SYN_SENT 192.168.100.3 7890 145.12.131.7 54324 TCP ESTABLISHED
表中条目 包含如下内容:
内部私有 IP 地址:局域网中设备的私有 IP 地址。 内部端口号:发送数据包的私有网络设备所使用的端口号。 外部公有 IP 地址:路由器在广域网(WAN)侧使用的 IP 地址,通常是单个 IP 地址,但也可能有多个。 外部端口号:与内部端口号对应的,由 NAT 分配用于标识特定会话的公有端口号。 协议类型:数据包使用的协议(如 TCP、UDP 等)。 NAT 表的条目通常是动态创建的。当内部设备发起到外部网络的连接时,路由器会在 NAT 表中创建一个条目。通过 NAT 表,路由器可以将从外部网络收到的数据包转发到正确的内部设备。当 NAT 表中的条目因为超时或者 NAT 表容量限制而被删除时,新的数据包会触发创建新的 NAT 条目。
地址转化过程 NAT 的地址转化过程如下所示,分为数据包进入公网 或者 进入内网:
当内网 IP 数据包经过 NAT 路由器向外部发送时,其源 IP 地址和端口会被修改成公有 IP 地址和公有端口。 当 IP 数据包经过 NAT 路由器被发送往内网的某个机器时,其目的 IP 地址和端口会被修改位私有 IP 地址和私有端口。 私有 IP 地址 内网地址(私有 IP 地址)包含以下三个范围:
10.0.0.0/8:从 10.0.0.0 到 10.255.255.255,用于大型网络和企业网172.16.0.0/12:172.16.0.0 到 172.31.255.255,用于中型网络192.168.0.0/16:192.168.0.0 到 192.168.255.255,用于小型网NAT 的 优势 主要在于如下几点:
安全性增强:通过隐藏内部网络的真实结构,NAT 提供了一定程度的安全性,可以有效减少攻击者直接访问内部网络的机会。 地址空间节省:NAT 允许多个设备使用单一的公共 IP 地址,这有助于缓解 IPv4 地址枯竭的问题,尤其是在大规模部署中。 IPv4 地址重用:NAT 允许内部网络使用私有 IP 地址,因此可以重复使用相同的私有 IP 地址范围,而不会与其他网络冲突。 路由器 IP 地址 路由器的接口 IP 地址配置根据连接类型有所不同,以下是两种常见场景的说明:
当两个路由器通过直接链路相连时,通常使用小型子网进行 IP 地址分配,例如 IPv4 的 /30 子网。此子网提供两个可用的主机 IP 地址,分别分配给两个路由器的接口。这种配置高效利用 IP 地址资源,适用于点对点链路。
当路由器的接口连接到一个局域网(LAN)或子网时,该接口会被分配该子网内的一个 IP 地址。通常,路由器接口会配置为子网的第一个或最后一个可用 IP 地址,并作为该子网内设备的 默认网关
通过合理配置 IP 地址,路由器能够有效实现网络互联和数据转发。
5 - 传输层 本章是计算机网络中的重点,需熟练掌握 TCP 的滑动窗口机制、连接断开与建立、流量和拥塞控制。
学习思维导图
# 传输层
## 提供的服务
- 传输层功能
- 寻址和端口
- 无连接和面向连接服务
## UDP协议
- UDP数据报
- UDP校验
## TCP协议
- TCP段
- 连接管理
- 可靠传输
- 流量控制
- 拥塞控制
传输层功能 数据分段与重组:传输层将上层应用层提供的数据流划分为较小的数据段,以便在网络中传输。在接收端,传输层负责将这些数据段重新组装成完整的数据流,以交付给应用层。 端口标识与多路复用:传输层使用端口号来标识不同的应用程序或服务。当多个应用程序同时运行时,传输层可以将它们的数据段混合在一起传输,并在接收端根据端口号将数据分发给正确的应用程序,从而实现多路复用。 会话管理:传输层还可以支持会话管理,包括建立、维护和终止与远程主机之间的通信会话。这是通过传输层协议中的握手和挥手过程来实现的,例如 TCP 握手过程。 差错检测与纠正:传输层可以检测并纠正数据传输过程中的错误,确保数据的完整性和正确性。这通常涉及使用校验和和纠错码等技术。 5.1 - TCP TCP 是计算机网络中重点,需要熟练掌握 TCP 的可靠传输机制,包含连接建立和断开、流量控制、拥塞控制,常常在选择题和大题中出现。
TCP 特点 面向连接:发送数据前后需要分别通过三次握手和四次挥手进行连接的建立和断开。 可靠交付:保证数据传输的无差错、不丢失、不重复、有序。 面向字节流:以滑动窗口的形式对字节按照顺序进行发送和接收。 全双工:通信双方在一个 TCP 连接中都可以发送和接收数据。 TCP 首部 Source Port (16) Sequence Number (32) Options Data Destination Port (16) Acknowledgement Number (32)
Acknowledgement Number (32) Checksum (16) Urgent (16) Window (16) Header... Reserved (6) Flags (6) TCP Header Bit 0 Bit 15 Bit 16 Bit 31 20 Bytes Text is not SVG - cannot display 源端口号(Source Port):16 位字段,指示发送端的端口号。 目标端口号(Destination Port):16 位字段,指示接收端的端口号。 序列号(Sequence Number):32 位字段,用于标识 TCP 报文段中第一个数据字节的序列号。这个字段用于实现 TCP 的可靠性机制,如数据的按序传递和重传。 确认号(Acknowledgment Number):32 位字段,如果设置了 ACK 标志位,该字段包含了期望接收的下一个数据字节的序列号。这个字段用于确认已经成功接收的数据。 数据偏移(Data Offset):4 位字段,指示 TCP 首部的长度,以 32 位字为单位。这个字段用于指示首部的长度,因为 TCP 首部长度可以变化,根据选项的存在而变化。 保留(Reserved):6 位字段,保留供未来使用,目前必须设置为 0。 控制标志位(Flags):TCP 报文段的控制标志,共有 6 个标志位,它们分别是:URG(紧急指针有效位):用于指示紧急数据。 ACK(确认位):用于指示确认号字段有效。 PSH(推送位):用于指示接收端应立即交付数据给应用层,而不需要等待缓冲区满。 RST(复位位):用于强制释放连接,重置连接状态。 SYN(同步位):用于建立连接,用于初始化序列号。 FIN(终止位):用于关闭连接。 窗口大小(Window Size):16 位字段,指示发送端的可用接收窗口大小。接收端可以根据这个字段的值来告诉发送端可以发送多少数据而不会导致拥塞。 校验和(Checksum):16 位字段,用于检测 TCP 首部和数据部分的传输中的错误。 紧急指针(Urgent Pointer):16 位字段,仅当 URG 标志位设置时才有效。用于指示紧急数据的末尾位置。 选项(Options):可选字段,用于包含一些额外的控制信息,如最大报文段长度、时间戳等。长度可变,最长可达 40 字节。 填充(Padding):根据选项字段的长度而变化,用于确保 TCP 首部的总长度是 32 位的倍数。 三次握手 第一次握手(SYN-SENT):发送方:将 SYN(同步)标志位设置为 1,表示发起连接请求。 序列号(Sequence Number):这是一个 32 位字段,用于标识发送方的 初始序列号 (ISN ,Initial Sequence Number),用于后续的数据传输。ISN 是一个随机数,用于防止连接重放攻击。 确认号(Acknowledgment Number):在第一次握手中,确认号字段被设置为 0,因为此时还没有确认数据的传输。 第二次握手(SYN-RECEIVED):接收方:接收到第一次握手的 TCP 报文段后,将 SYN 标志位设置为 1,表示同意建立连接。 序列号(Sequence Number):接收方生成自己的初始序列号(ISN),并将其放入序列号字段。 确认号(Acknowledgment Number):此时确认号字段被设置为发送方的初始序列号加 1,表示接收到了第一次握手中的序列号。 第三次握手(ESTABLISHED):发送方:接收到第二次握手的 TCP 报文段后,将 SYN 标志位设置为 0(因为连接已经建立),并将 ACK(确认)标志位设置为 1,表示确认接收到了第二次握手中的序列号。 序列号(Sequence Number):发送方生成一个新的序列号,用于后续的数据传输。 确认号(Acknowledgment Number):此时确认号字段被设置为接收方的初始序列号加 1,表示接收到了第二次握手中的序列号。 第三次握手可以携带应用层数据么?
当然可以,你可以想一下,如果发送方还需要收到第三次握手的确认才可以发送数据的话,不就变成四次握手了么,这是不合理的。
不同的 TCP 实现对此有不同的处理方式,有的 TCP 实现是不会将数据放到第三次握手的报文中,有的则会,正确的协议实现对于这两种情况应该都能够正确处理。
四次挥手 FIN-WAIT-1 CLOSE-WAIT ESTABLISHMENT FIN=1... ACK = 1... ACK = 1
ACK = 1... FIN = ACK = 1
FIN = ACK = 1... FIN-WAIT-2 TIME-WAIT ESTABLISHMENT LAST-ACK Text is not SVG - cannot display 客户端发送连接关闭请求客户端首先决定不再发送数据,并希望关闭连接。 客户端向服务器端发送一个 TCP 报文,其标志位中包含 FIN(Finish)标志,表示客户端已经完成数据的发送任务。 客户端进入 FIN-WAIT-1 状态,等待服务器的确认。 服务器端确认客户端的关闭请求服务器端接收到客户端的 FIN 报文,知道客户端不再发送数据。 服务器端向客户端发送一个 ACK(Acknowledgment)报文作为确认,表示它已收到了客户端的关闭请求。 服务器端进入 CLOSE-WAIT 状态,表示服务器端已经完成数据的发送任务,但仍然可以接收来自客户端的数据。 服务器端关闭连接服务器端完成了数据的发送任务后,也想要关闭连接。 服务器端向客户端发送一个 FIN 报文,告知客户端它已经完成了数据的发送,并请求关闭连接。 服务器端进入 LAST-ACK 状态,等待客户端的确认。 客户端确认服务器端的关闭请求客户端接收到服务器端的 FIN 报文后,确认服务器端的请求。 客户端向服务器端发送一个 ACK 报文作为确认。 此时客户端进入 TIME-WAIT 状态,等待足够的时间,以确保服务器端收到了确认,然后再关闭连接。 第一次挥手一定是客户端发起么?
第一次挥手是由发起连接关闭的一方发送的,通常情况下是客户端发送。但在某些特殊情况下,服务器端也可以主动发起连接关闭,不过这种情况相对较少见。
滑动窗口机制 上图是滑动窗口的简图,滑动窗口代表当前 发送方正在发送 以及 接收方正在接收的 数据窗口,数据窗口是所有数据中的一部分。
每当发送方收到接收方的 ACK 确认后,滑动窗口就会向前滑动。这样,窗口中新位置允许新的数据发送
滑动窗口的大小表示发送方在未收到接收方确认(ACK)的情况下,最多可以发送多少字节的数据。窗口大小由接收方决定,并通过 ACK 报文中的窗口字段告知发送方。
绝对下标和序列号的概念区别
绝对下标(Absolute Number)
指的是在整个 TCP 会话期间,数据字节在传输流中的位置,其大小无上限。可以把它想象成一个 TCP 连接中从第一个字节开始的整体计数器。例如,如果一个 TCP 连接传输了 5000 字节的数据,那么这些数据的绝对下标范围是从 1 到 5000。
序列号(Seqno,Sequence Number)是一个 32 位的非负数(unsigned),是 TCP 报文段中实际使用的一个字段,从一个随机的初始序列号(ISN)开始计数。
在 TCP 发送和接收数据时,其需要将 序列号 和 绝对下标 进行转换,假设第一次握手使用的序列号为 ISN,那么绝对下标 index 对应的序列号为 (index + 1 + ISN) & UINT32_MAX。
如果接收方接收到的序列号为 seqno,那么对应的绝对下标为 (seqno - ISN - 1 + UINT32_MAX) % UINT32_MAX + n * UINT32_MAX,其中这里 n 为一个整数,取决于滑动窗口在 [0, UINT32_MAX] 的区间内移动了几个来回。
以上大家思考一下,不会具体考察,但是思考过程可以帮助大家理清楚这两个概念,并且能够加深对于滑动窗口的理解。
可靠传输机制 TCP 的可靠传输通过多种机制共同实现,下文将对三个关键机制进行介绍。
序列号和确认号 序列号(seqno, sequence number)和 确认号(ackno, acknowledge number)是 TCP 首部的两个字段,TCP 协议通过 序列号 来记录目前已经发送了哪些数据,通过 确认号 记录哪些数据已经被接收方所接收。
发送方发送序列号 和 接收方返回确认号 的交互可能存在以下几种情况:
如果发送的数据段丢失了,接收方不会发送更新的确认号,这会最终导致发送方超时并重传丢失的数据段。 如果数据段到达了接收方,但是是乱序的,接收方将持续发送最后一个正确序列号的确认,提示发送方其中有数据段需要重新传输。 如果数据段到达了接收方,并且是按顺序的,接收方发送一个新的确认号,提示发送方到目前为止的所有数据都已正确接收。 超时重传 TCP 协议在发送一个 数据段(segment)时,它会记录目前正在传输的 segment,并为每一个 segment 设置一个定时器。
如果某个 segment 的定时器超时了,就说明发送方在 超时时间阈值 内没有接收到该 segment 的确认,发送方就会触发超时重传(Retransmission Timeout),重新发送超时的 segment。
超时重传的时间时如何确定的? (了解即可)
超时重传的时间 Timeout 可以通过如下公式计算得到:
$$
\begin{align*}
\text{\small Timeout} &= \text{\small EstimatedRTT} + 4*\text{\small DevRTT} \\
\text{\small EstimatedRTT} &= (1-\alpha) * \text{\small EstimatedRTT} + \alpha * \text{\small SampleRTT} \\
\text{\small DevRTT} &= (1-\beta) * \text{\small DevRTT} + \beta * \left|\text{\small SampleRTT} - \text{\small EstimatedRTT}\right|
\end{align*}
$$
SampleRTT 是每一次报文往返时间的样本,EstimatedRTT 是加权平均的往返时间,DevRTT 是往返时间的偏差,而 $\alpha$ 和 $\beta$ 是权重,通常取值为 $\alpha=0.125, \beta=0.25$。
校验和 TCP 首部包含一个校验和(Checksum)字段,用于检测数据在传输过程中的任何变化。如果接收方检测到校验和错误,该数据段会被丢弃,然后接收方会要求发送方重传该数据段。
TCP 的校验和计算方法和 IP 校验和计算方法 一致,不过两者校验的范围和目的有所不同。
其 IP 校验和只针对 IP 头部进行校验,主要用于检测数据在传输过程中由于网络故障等原因造成的错误。
而 TCP 校验和不仅要校验 TCP 头部,还要校验 TCP 载荷(即数据部分)。因此,TCP 校验和能提供更全面的错误检测。
流量控制 TCP(Transmission Control Protocol)流量控制是一种机制,用于确保在网络中的发送方和接收方之间协调数据传输速率,以防止接收方不堪重负并避免数据包的丢失。TCP 流量控制的主要目标是保证数据的可靠传输,同时有效地利用可用的网络带宽。
TCP 通过 滑动窗口机制 来实现流量控制:发送方根据接收方通告的窗口大小发送数据,而接收方根据自己的处理速度和可用内存来控制窗口大小。
窗口大小(Window Size):TCP 流量控制使用窗口大小来管理数据流的速率。窗口大小表示发送方可以在没有接收方确认的情况下发送的未被确认的数据量。窗口大小由接收方通过 TCP 报文中的通告窗口字段通知发送方。 滑动窗口的调整:窗口大小是动态调整的,它会根据网络条件和接收方的状态而变化。如果接收方的缓冲区快满了,通告窗口大小可能会减小,以减缓发送速率;如果接收方的缓冲区有足够的空间,通告窗口大小可能会增大,以提高发送速率。 零窗口控制:如果接收方的缓冲区已满,它可以将窗口大小设置为零,表示不接受任何数据。发送方会注意到这一点并暂停数据的发送,直到接收方准备好接收数据。 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Usable... TCP... Sent and Acked Sent and not acked Not sent
Not sent... Not Sent
Not Sent... * * * * * * Text is not SVG - cannot display TCP 的发送窗口可以按照逻辑划分为四个部分:
已经发送并且被确认的数据(字节流) 已经发送但还没有被确认 尚且还没有发送 暂时不可以发送 其中第 2、3 个部分构成 TCP 的发送窗口,当发送方收到 ackno 在第 2 个部分内的确认报文时,调整滑动窗口的大小后向前移动滑动窗口,并且发送接下来可以发送的数据。
13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Available... TCP... Received and Accepted
Received and Accepted... Received but not accepted
Received but not accepted Not Received Not ready to be received * * * * * * Text is not SVG - cannot display TCP 的接收窗口可以按照逻辑划分为四个部分:
已经被应用层接收的数据 已经被 TCP 接收,但是还没有被应用层接收的数据 还没有接收到的数据 还不可以接收到的数据 拥塞控制 tcp 的拥塞控制指的是 tcp 限制传输数据的速率,进而防止注入过多的数据到网络中,进而造成网络链路过载。
大家需要了解,tcp 不是一个“自私”的算法,一段链路上可以同时包含很多 tcp 连接,tcp 的拥塞控制的目的是尽量去实现一个总体的最优,而不是个体的最优。当 tcp 检测到数据传输出现拥塞之时,即一段时间内没有接收到一些确认,它就会降低自己传输数据的速率。
需了解如下的 TCP 拥塞控制算法:
慢开始 慢开始是 TCP 连接开始时的一个阶段,相较于直接以较高的速率发送数据,慢开始会以一个较低的速率开始,然后逐步试探当前网络传输的能力,以指数的速率增加发送速率。慢开始的流程如下:
初始化:当一个 TCP 连接开始时,拥塞窗口 cwnd 设置为一个很小的值,通常是 1MSS (最大段大小)。 指数增长:对于每个收到的 ACK , cwnd 会增加一个 MSS 。这意味着每个 RTT (往返时间) cwnd 都会翻倍,导致了指数增长。 转换阈值:当 cwnd 达到 ssthresh (慢开始阈值)时, TCP 会从慢开始模式转换到拥塞避免模式。 cwnd 在到达 ssthresh 之前指数型增长
什么是 MSS?
MSS 是 Maxium Segment Size 的简称,即最大段大小。MSS 通常是根据网络路径的 MTU(最大传输单元)来确定的,MTU 是网络层上一种数据包最大尺寸的限制,常见的 MSS 值为 1460 字节(MTU 1500 字节减去 IP 头部和 TCP 头部的大小)。
拥塞避免 线性增长:在这个阶段,每收到一个 ACK, cwnd 增加 1/cwnd 的大小。这导致了每个 RTT , cwnd 只增加约一个 MSS ,这是一个线性的增长。 拥塞检测:如果发生了超时或者收到三个重复的 ACK (意味着网络中的数据分段丢失),则认为发生了网络拥塞。此时, ssthresh 会被设置为当前 cwnd 的一半,并将 cwnd 重新设置为 1MSS ,然后重新进入慢开始阶段。 快速重传 传统的 TCP 重传是基于重传计时器的:当计时器到期而没有收到 ACK 时,TCP 会重新发送数据(超时重传)。然而,在有高带宽或低延迟的网络中,等待这个计时器到期可能是低效的。
快速重传 机制是当发送方连续收到三个重复的 ACK(表示同一个数据段)时,它会立即重传下一个待确认的数据段,而不是等待重传计时器到期。这三个重复的 ACK 是网络中丢失一个分段的一个早期指示。
一旦触发了快速重传,TCP 进入 快速恢复 模式,按照书上的说法,触发了快速重传后,ssthresh 和 cwnd 都被设定为快速重传前 cwnd 值的一半,然后执行拥塞避免算法。
但是在实际 TCP 的实现中 ssthresh 被设定为当前 cwnd (拥塞窗口)的一半。同时, cwnd 也会被设定为 ssthresh 加上三个 MSS (最大段大小),然后执行如下策略:
cwnd 的增加:在快速恢复期间,每当收到一个重复的 ACK , cwnd 都会增加一个分段的大小。这是为了用新的数据分段平衡可能在传输路径中出现的丢失。退出快速恢复:当发送方接收到一个新的、非重复的 ACK ,这表示之前丢失的分段已被成功接收。这时, TCP 会退出快速恢复模式,并将 cwnd 设置为 ssthresh 的值,然后进入拥塞避免阶段。 这里注意一下即可,考试考到的话按照书中方式计算 cwnd。
TCP slow start and contgestion avoidance
TCP fast retransmit and fast recovery
Fast retransmit
总结一下:
当 cwmd < ssthresh 时,使用慢开始算法,swnd 以指数增长 当 cwmd >= ssthresh 时,使用拥塞避免算法,swnd 线性增长 当在 RTO 内没有收到发送的某个分组的确认时如果启动了快速恢复,则设置 cwnd = ssthresh = cwnd / 2,开始使用拥塞控制算法 如果没有启动快速恢复,则设置 ssthresh = cwnd / 2, cwnd = 1,开始使用慢开始算法 如果启用了快速重传,并且收到 3 个与先前重复的 ACK(总共收到 4 个相同的 ACK),则不用等待超时器 RTO 结束,可以马上重传该数据包,cwnd 可能会减少(这里不考察) 窗口大小 初始窗口大小 TCP 连接的初始窗口大小可以根据 TCP/IP 协议栈的实现和操作系统的配置而有所不同。通常情况下,初始窗口大小是根据 TCP 的初始拥塞窗口(Initial Congestion Window,ICW)来确定的。
RFC 6928 建议了一种用于确定 TCP 连接初始拥塞窗口大小的算法,该算法是根据实验和观察得出的最佳实践。根据这个 RFC,初始拥塞窗口大小(ICW)的推荐值为 10 个 MSS(了解即可)。
发送窗口大小 发送窗口大小为拥塞窗口和接收窗口中的较小值,swnd = min(cwnd, rwnd),当发送方收到来自接收方的确认报文时,会根据其中的 window 字段来调整 rwnd 大小,也会根据收到的确认信息或者超时去调整 cwnd 的大小。当 cwnd 或者 rwnd 变化时,会调整 swnd 的大小。
接收窗口大小 接收方会根据自身处理能力和缓冲区的情况来动态调整窗口大小。如果接收方的应用程序不能及时处理接收到的数据,或者接收方的缓冲区已经满了,它就会减小窗口大小,以通知发送方降低发送速率。
5.2 - UDP 了解 UDP 的概念和应用,对比与 TCP 的不同,可能在选择题中考察。
UDP 数据报 UDP(User Datagram Protocol)首部的长度固定为 8 个字节(64 位),不论 UDP 携带的数据量大小如何,其首部都保持不变。UDP 首部的各个字段如下:
源端口(Source Port):占用 2 个字节(16 位),用于标识发送方应用程序的端口号。 目标端口(Destination Port):占用 2 个字节(16 位),用于标识接收方应用程序的端口号。 长度(Length):占用 2 个字节(16 位),指示 UDP 数据报的总长度,包括首部和数据。因此,最小长度为 8 字节。 校验和(Checksum):占用 2 个字节(16 位),用于检测 UDP 数据报在传输过程中是否受到损坏。 当传输层从 IP 层收到 UDP 数据报时,就根据首部中的目的端口,把 UDP 数据报通过
相应的端口,上交最后的终点一一应用进程,如下图所示:
若接收方 UDP 发现收到的报文中的目的端口号不正确(即不存在对应于端口号的应用进程),则就丢弃该报文,并由 ICMP 发送“端口不可达”差错报文给发送方。
UDP 校验 UDP 的校验和(checksum)用于检测数据在传输过程中是否发生错误。它覆盖 UDP 头部、数据部分以及部分 IP 头部信息(伪头部),确保数据的完整性。
这种简单的差错检验方法的校错能力并不强,但它的好处是简单、处理速度快。
发送端 UDP 的发送方需要计算 checksum 字段的值,并且填充进 UDP 首部相应字段中。
发送方计算 checksum 包含构造伪首部、组合校验数据、计算 16 位和、按位取反四个步骤。
构造伪头部 为了确保源和目的地址的正确性,UDP 校验和包含一个伪头部(不实际传输,仅用于计算)。伪头部包括:
源 IP 地址(32 位,IPv4) 目的 IP 地址(32 位,IPv4) 协议字段(8 位,UDP 为 17) UDP 长度(16 位,UDP 头部 + 数据的总字节数) 填充位(8 位,通常为 0,确保伪头部长度为 12 字节) 组合校验数据 将以下内容按 16 位分组:
伪头部 UDP 头部(包括源端口、目的端口、长度、校验和字段,校验和字段初始置 0) 数据部分(若数据长度为奇数字节,末尾补 0 凑成 16 位) 计算 16 位和 将所有 16 位数逐一相加,记录进位。 如果有进位(和超过 16 位),将进位加到低 16 位(称为 回卷 )。 例如:若两个 16 位数相加得 1 0000 0000 0000 0001,则取低 16 位 0000 0000 0000 0001 并加 1,得 0000 0000 0000 0010。 按位取反 对最终的 16 位和按位取反(0 变 1,1 变 0),得到校验和。 将此校验和填入 UDP 头部的校验和字段。 特殊情况 如果校验和计算结果为全 0,则发送 1111 1111 1111 1111(全 1),以避免与“校验和禁用”(全 0)混淆。 UDP 校验和是可选的,若不使用,校验和字段置为全 0。 检验时,若 UDP 数据报部分的长度不是偶数个字节,则需填入一个全 0 字节进行填充
若 UDP 检验和检验出 UDP 数据报是错误的,则可以丢弃,也可以交付给上层,但是需要附上错误报告,即告诉上层这是错误的数据报。
计算 16 位和的过程中,如果有进位,不要忘记“回卷”。
接收端 接收端通过以下步骤验证数据完整性:
提取校验数据 :接收端同样构造伪头部(使用接收到的 IP 头部信息),并提取伪首部、UDP 首部(包括接收到的校验和)、数据部分。计算 16 位和 :将所有 16 位数(包括接收到的校验和)相加,记录并回卷进位。如果数据无误,和的结果应为 1111 1111 1111 1111(全 1)。验证结果 如果最终和为全 1,说明数据正确,无错误。 如果和不为全 1,说明数据在传输中发生错误,接收端通常丢弃该数据报(UDP 不负责重传)。 处理特殊情况 如果接收到校验和为全 0,表示发送端禁用了校验和,接收端可直接接受数据(不校验)。 如果校验和为全 1,需按上述步骤验证。 实例 假设我们要发送一个 UDP 数据报,相关信息如下:
源 IP 地址:192.168.1.1(二进制:11000000 10101000 00000001 00000001) 目的 IP 地址:192.168.1.2(二进制:11000000 10101000 00000001 00000010) 源端口:1024(二进制:00000100 00000000) 目的端口:2048(二进制:00001000 00000000) 数据:0x48656C(3 字节,“Hel”) 则得到 16 位组合数据和校验和计算过程如下所示:
计算得到的校验和为:00111011 00011111(十六进制:0x3B1F)。
当接收端接收到 UDP 数据报是,接收端将所有 16 位数(包括校验和 00111011 00011111)相加:
重复上述加法,最后一步加上校验和:11000100 11100000 + 00111011 00011111 = 11111111 11111111(全 1)
UDP 特点 无连接性:UDP 是一种无连接的协议,这意味着在发送数据之前,发送方和接收方之间不建立连接。每个 UDP 数据报都是独立的,没有先后顺序的要求。 轻量级:UDP 非常轻量级,因为它不涉及连接建立和维护,也不包括复杂的拥塞控制算法。这使得 UDP 非常适用于低延迟和高吞吐量的应用。 无序性:UDP 数据报在传输过程中不保持顺序。这意味着发送方发送的多个 UDP 数据报可能以不同的顺序到达接收方,并且接收方需要自行处理数据的顺序问题。 不可靠性:UDP 不提供可靠性。它不保证数据的传输成功,也不负责重新发送丢失的数据。如果数据在传输过程中丢失或损坏,接收方将不会收到任何通知,并且需要根据应用程序的要求自行处理这些问题。 广播和多播:UDP 支持广播和多播,允许一个 UDP 数据报同时发送到多个接收方。 应用场景 UDP 常用于 一次性传输较少数据 的网络应用,如 DNS、SNMP 等,因为对于这些应用,若采用 TCP,则将为连接创建、维护和拆除带来不小的开销。
UDP 也常用于 对延迟敏感 多媒体应用(如 电子游戏、实时视频会议、流媒体等),显然,可靠数据传输对这些应用来说并不是最重要的,
但 TCP 的拥塞控制会导致数据出现较大的延迟,这是它们不可容忍的。
UDP 不保证可靠交付,但这并不意味着应用对数据的要求是不可靠的,所有维护可靠性的工作可由用户在应用层来完成。应用开发者可根据应用的需求来灵活设计自己的可靠性机制。
比如 HTTP3 中使用的 QUIC 就是在 UDP 的基础上实现的一种可靠传输协议。
6 - 应用层 可能会在选择题中考察,主要涉及到一些应用层协议的基本概念。
学习思维导图:
# 应用层
## 网络应用模型
- C/S模型
- P2P模型
## DNS系统
- 层次域名空间
- 域名服务器
- 域名解析过程
## FTP
- FTP协议的工作原理
- 控制连接和数据连接
## 电子邮件
- 电子邮件系统的组成结构
- 电子邮件格式和MIME
- SMTP协议与POP3协议
## WWW
- 概念和组成结构
- HTTP协议
6.1 - 网络应用模型 了解 CS 模型和 P2P 模型的概念,可能在选择题中考察。
C/S 模型 C/S(Client Server)模型:中心化、依赖服务器,适合稳定服务场景。
核心特点:客户端(用户设备,如电脑、手机)向服务器(提供服务的专用设备)请求资源或服务,服务器响应并提供支持。 通信方式:基于 “请求 - 响应” ,客户端主动发起,服务器被动应答。 架构:中心化 ,服务器是核心枢纽,客户端依赖服务器获取服务。 典型例子:浏览网页(浏览器与 Web 服务器)、收发邮件(邮件客户端与邮件服务器)。 P2P 模型 P2P(Peer to Peer):分布式、节点平等,适合资源共享和去中心化场景。
核心特点:网络中 设备对等 ,既是客户端又可作服务器,共同协作共享资源。 通信方式:设备直接互联,点对点通信 ,无需中心服务器。 架构:分布式,去中心化 ,资源分散在各节点,网络更灵活。 典型例子:文件共享(如 BitTorrent)、音视频通话(如 Skype)、区块链(如比特币)。 6.2 - DNS 了解 DNS 的功能以及域名查询的步骤,可能在选择题中考察。
层次域名空间 DNS 使用层次域名空间来组织域名,将域名划分为多个级别,每个级别之间以点(.)分隔。域名从右到左逐级递增,最右边是顶级域名(TLD),然后是二级域名,三级域名,以此类推。
例如, www.example.com 中, .com “是顶级域名, example.com 是二级域名, www.example.com 是子域名。
DNS 层次域名空间的设计使得域名分布在不同的管理区域中,每个管理区域负责管理其自己的域名空间。这种分层结构有助于提高 DNS 的可扩展性和效率。
域名服务器 根域名服务器 (Root Name Servers):这些服务器位于 DNS 解析的最顶端。它们不直接回答关于哪个域名映射到哪个 IP 地址的查询,而是告诉查询者下一步应该询问哪个顶级域名 (TLD) 服务器。 根服务器的数量是有限的,并且它们的位置在全球都是已知的。 顶级域名服务器 (Top-Level Domain Name Servers, TLD Name Servers):这些服务器负责特定的顶级域名(如 .com, .org, .net 等)。它们为下一级的域名(如 example.com)提供有关权威名称服务器的信息。 权威域名服务器 (Authoritative Name Servers):这些服务器为特定的域名(如 example.com)提供详细的 DNS 记录信息(例如 A 记录、MX 记录等)。只有权威服务器才能为其负责的域名提供这些信息。 大多数组织拥有权威 DNS 服务器来为他们的域名提供解析服务。 本地域名服务器 (Local Name Server)是在本地网络环境中运行的 DNS 服务器,它为该网络中的设备提供域名解析服务。 每个 ISP 或一所大学都可以有一个本地域名服务器。 域名解析过程 域名解析分为 递归查询 和 迭代查询 两种。
递归查询 客户端向递归服务器发送一个请求,比如解析 www.example.com。 如果递归服务器没有缓存结果,它会从根服务器开始,逐级查询:首先查询根域名服务器(Root Server),获取顶级域(TLD)的服务器地址。 再查询 TLD 服务器(比如 .com),获取权威服务器的地址。 然后查询权威服务器,最终获取目标域名的 IP 地址。 递归服务器将最终的 IP 地址返回给客户端。 迭代查询 客户端向本地 DNS 服务器(或根服务器)发送查询请求,比如解析 www.example.com。 根服务器返回 .com 顶级域的 DNS 服务器地址。 客户端再向 .com 顶级域 DNS 服务器发送查询请求。 .com 顶级域返回 example.com 的权威服务器地址。客户端向 example.com 的权威服务器发送查询请求,获取最终的 IP 地址。 DNS 递归查询 和 迭代查询的不同点如下表所示:
特点 递归查询 迭代查询 查询责任 DNS 服务器负责查询所有结果 客户端逐级查询 查询复杂度 客户端简单,只需发起一次请求 客户端复杂,需要多次查询 使用场景 用户设备、本地 DNS 服务器 DNS 服务器之间的交互 性能 服务器负担较大 服务器负担较小
DNS 缓存 无论是浏览器、操作系统,还是本地的递归 DNS 服务器,在接收到域名解析结果之后,都会将其暂时保存在本地缓存中。这样,如果同一个域名在短时间内被多次请求,就可以直接从缓存中获取结果,而不需要再次向外部服务器发送查询请求。
DNS 记录中包含一个名为 TTL(Time to Live)的字段,用于指定这条记录可以在缓存中保存多久。比如 TTL 为 3600 表示记录在缓存中可保留 3600 秒(即一小时)。在这段时间内,只要有查询,就可以直接使用缓存的结果。当 TTL 到期后,缓存记录会被丢弃,下一次查询将重新走完整的解析流程。
6.3 - FTP 了解 FTP 的工作原理和两种连接方式,可能在选择题中考察。
工作原理 建立连接:FTP 通常使用 TCP 作为传输层协议。客户端和服务器之间首先建立一个 TCP 连接。FTP 默认使用两个端口,一个用于控制连接(命令连接,通常是端口 21),另一个用于数据传输连接。 身份验证:一旦建立了控制连接,客户端需要提供用户名和密码以进行身份验证。有些 FTP 服务器还支持匿名 FTP,允许用户使用一个通用的用户名(通常是"anonymous")和电子邮件地址作为密码进行访问。 命令与响应:控制连接用于传输 FTP 命令和服务器的响应。客户端可以向服务器发送各种 FTP 命令,如上传文件、下载文件、列出目录内容等。服务器将对每个命令响应一个状态码,指示命令执行的结果(例如,成功、失败等)。 数据连接:当需要传输文件或目录列表时,FTP 使用数据连接来进行实际的数据传输。数据连接可以以两种方式之一建立: 主动模式(Active Mode):客户端打开一个本地端口,并通知服务器连接到该端口以进行数据传输。 被动模式(Passive Mode):服务器打开一个本地端口,并通知客户端连接到该端口以进行数据传输。 数据连接用于传输文件的内容或目录列表等信息。 文件传输:一旦建立了数据连接,文件传输开始。客户端可以向服务器上传文件(将本地文件发送到服务器)或下载文件(从服务器获取文件)。 文件传输可以在 ASCII 模式和二进制模式之间切换。ASCII 模式适用于文本文件,而二进制模式适用于二进制文件(如图像、音频等)。 关闭连接:一旦文件传输完成或用户完成 FTP 会话,客户端可以发送 QUIT 命令以终止 FTP 连接。服务器会响应,并关闭连接。 控制连接和数据连接 控制连接(Control Connection):控制连接是 FTP 会话的首要连接,通常使用 TCP 的 端口 21 。 控制连接用于传输 FTP 命令和服务器的响应,用来 控制 FTP 会话的行为 。客户端通过控制连接向服务器发送各种 FTP 命令,如登录、列出文件目录、切换工作目录等。 服务器通过控制连接发送状态码和响应消息,以指示每个 FTP 命令的执行结果(例如,成功、失败等)。 控制连接始终保持打开状态(持久连接 ),直到用户完成 FTP 会话,或者用户发送 QUIT 命令以终止连接。 数据连接(Data Connection):数据连接用于实际的文件传输,以及在某些情况下,传输文件的目录列表信息。数据连接通常使用不同的端口,其端口号由控制连接中的 FTP 命令指定。 有两种主要的数据连接模式: 主动模式(Active Mode):在主动模式下,客户端在一个本地端口打开,并通过控制连接告知服务器连接到该端口以进行数据传输。服务器主动连接到客户端的本地端口。 被动模式(Passive Mode):在被动模式下,服务器在一个本地端口打开,并通过控制连接告知客户端连接到该端口以进行数据传输。客户端主动连接到服务器的本地端口。 数据连接用于上传文件(将文件从客户端发送到服务器)和下载文件(从服务器获取文件)。 6.4 - 电子邮件 了解 SMTP 和 POP3 协议,可能在选择题中考察。
电子邮件系统 电子邮件系统由 用户代理、邮件服务器 以及 电子邮件协议 这三个核心组成部分协同工作,确保邮件的发送、接收和存储。
用户代理 用户代理(UA, User Agent)是用户与电子邮件系统交互的接口,通常是邮件客户端软件(如 qq 邮箱网页界面、Outlook 等)。
功能:
提供用户友好的界面,用于撰写、发送、接收和阅读邮件。 管理邮件文件夹(如收件箱、已发送、草稿)。 与邮件服务器通信以发送或获取邮件。 邮件服务器 邮件服务器(Mail Server)是电子邮件系统的核心,负责存储、转发和管理邮件。
功能:
接收来自用户代理的邮件并存储。 根据邮件的目标地址,通过 SMTP 协议将邮件转发到目标邮件服务器。 提供邮件存储功能,供用户通过 POP3/IMAP 协议访问。 SMTP SMTP(Simple Mail Transfer Protocol)是用于邮件发送的标准协议,负责在邮件服务器之间或从用户代理到邮件服务器传输邮件。
功能:
定义了邮件如何从发送方传递到接收方的邮件服务器。 工作在 TCP/IP 协议之上,通常使用端口 25(或加密端口 587)。 仅负责邮件的发送,不涉及邮件的接收或存储。 工作流程:
用户代理通过 SMTP 将邮件发送到发送方的邮件服务器。 发送方服务器通过 SMTP 与接收方服务器通信,将邮件传递到目标服务器。 POP3 POP3 是用于从邮件服务器检索邮件的协议,允许用户将邮件下载到本地设备。
功能:
用户代理通过 POP3 连接到邮件服务器,下载邮件到本地。 默认情况下,邮件下载后会从服务器删除(可配置保留)。 工作在 TCP/IP 协议之上,通常使用端口 110(或加密端口 995)。 工作流程:
用户代理通过 POP3 登录服务器。 下载新邮件到本地设备。 可选择删除服务器上的邮件副本。 需要注意的是,SMTP 使用的是“推送”(Push)方式进行通信。当用户代理发送邮件,或者邮件在邮件服务器之间传递时,SMTP 客户端会将邮件主动“推送”到 SMTP 服务器。而 POP3 则采用“拉取”(Pull)方式进行通信。当用户需要查看邮件时,用户代理会向邮件服务器发出请求,从服务器中“拉取”用户邮箱里的邮件。
电子邮件格式 一封电子邮件由 信封 和 内容 两部分组成,其中 邮件内容 又可分为 首部 和 主体 。首部格式 由 RFC 标准定义,而 主体部分 则由用户自由撰写。
用户在填写完邮件首部后,系统会自动提取信封所需的信息,无需用户手动填写信封内容。
邮件首部由若干 首部行 组成,每行格式为:关键字: 值。其中:
To:必填,指定一个或多个收件人的电子邮件地址,格式为 用户名@域名,如 abc@csgraduates.com。用户名在所属域名下必须唯一,从而保证该邮箱地址在整个互联网上唯一。Subject:可选,表示邮件主题,用于概括邮件内容。From:必填,表示发件人邮箱地址,通常由邮件系统自动填写。首部和主体之间用一个空行分隔。以下是一个典型邮件内容示例:
From: sender@example.com
To: abc@cskaoyan.com
Subject: Meeting Schedule
Dear team,
Please find the meeting schedule attached.
MIME MIME(Multipurpose Internet Mail Extensions,多用途互联网邮件扩展)是为了解决传统电子邮件格式的局限性而提出的一种扩展标准。
早期的电子邮件只能传输 纯文本 (ASCII 码),不支持发送图片、音频、视频或非英语字符(如中文)。这严重限制了电子邮件的用途。MIME 的出现,就是为了解决这些问题。
MIME 主要包含以下三点 核心功能 :
支持非 ASCII 字符允许使用 UTF-8 等编码发送包含中文、法语等字符的邮件内容。 支持多媒体内容可以发送图像(如 JPEG、PNG)、音频、视频等多种格式的附件或内嵌内容。 支持多部分内容(multipart)一封邮件可以同时包含文本和附件,甚至不同格式的内容(例如纯文本和 HTML 格式的正文)。 6.5 - 万维网 本节的重点在于了解 HTTP 协议的特点,报文组成部分以及一些首部选项,可能在选择题中考察。
WWW WWW,也称为万维网(World Wide Web),是一个信息系统,在这个系统中,文档和其他资源通过统一资源标识符(Uniform Resource Identifiers,或 URI,通常为 URL)进行标识和互相链接。用户可以使用网络浏览器访问万维网上的资源。
组成结构 URL (统一资源定位符):每个网页或资源都有一个唯一的地址,称为 URL,它定义了资源的位置和如何访问它。 HTTP/HTTPS (超文本传输协议/安全超文本传输协议):这是用于从服务器传输网页到浏览器的协议。 HTML (超文本标记语言):大多数网页使用 HTML 编写,它是用于描述和呈现超文本的标准标记语言。 HTTP 协议 HTTP(超文本传输协议)是互联网上应用最为广泛的一种网络协议。它是一个属于应用层的协议,常基于 TCP/IP 协议通信。HTTP 用于客户端和服务器之间的数据传输,特别是在万维网(WWW)中,用于传输网页(HTML 文件)以及与其关联的资源(如图片、音频、视频等)。
无状态 HTTP 本身不保持用户的状态信息,每个请求都是独立的,服务器无法识别是不是同一个用户发送的多个请求。这一点在现实中通常通过 Cookie 和 Session 技术来弥补。
组成部分 请求和响应:HTTP 通信通常包括客户端向服务器发送请求,然后服务器返回响应的过程。 方法:HTTP 定义了一组请求方法,用于表示对资源的不同操作:GET:请求指定资源。 POST:提交数据以供处理。 PUT:更新指定资源。 DELETE:删除指定资源。 HEAD:与 GET 相似,但只请求资源的头部信息。 OPTIONS:获取可以应用于目标资源的通信选项。 PATCH:对资源进行部分修改。 其他方法还包括 CONNECT, TRACE 等。 状态码:响应返回一个状态码,用于表示请求的结果,例如:200 OK:请求成功。 404 Not Found:资源未找到。 500 Internal Server Error:服务器内部错误。 以及其他众多状态码,用于表示不同的响应状态。 头部字段:HTTP 请求和响应都包含头部信息,提供有关请求或响应的元数据,例如 Content-Type(内容类型)或 User-Agent(用户代理)。消息体:请求或响应的主体部分,通常包含要传输的数据。例如,POST 请求的数据或服务器返回的网页内容。 关键字段 以下首部字段可能在考试中被考察,需要了解一下:
长连接和短连接 长连接和短连接含义
HTTP 根据首部的 keepalive 选项是否被设置被分为长连接和短连接。
长连接 短连接 HTTP 不同版本中的 keepalive
在 HTTP/1.0 中,持久连接不是默认行为。要在 HTTP/1.0 中启用它,必须在请求头部添加 Connection: keep-alive 。 在 HTTP/1.1 中及之后,持久连接是默认行为。如果想关闭它,必须在请求或响应头部添加 Connection: close 。 流水线和非流水线 open 流水线 close open 非流水线 close HTTP 流水线和非流水线含义
流水线(HTTP Pipelining):HTTP 客户端在未等待前一个请求的响应的情况下,连续发送多个 HTTP 请求。 非流水线(Non-pipelined):HTTP 客户端必须接收到上一个请求的响应,才能发送下一个请求。 HTTP 不同版本中的流水线支持
在 HTTP/1.0 中,流水线 的功能并不支持。 在 HTTP/1.1 中,引入了 HTTP 流水线 的支持,但由于使用中队头阻塞的问题,应用并不广泛。 在 HTTP/2 中,进一步改进了请求处理机制,允许多个请求和响应在同一个连接中并行进行,解决了队头阻塞的问题。 什么是队头阻塞(了解即可)
当多个请求被排成队列时,如果第一个请求由于某种原因(如延迟、丢包或慢速响应)未能及时处理,那么后续的所有请求都必须等待第一个请求的响应完成才能被处理。
在 HTTP/2.0 之前,你只有在完成上一个 HTTP 请求后,才能发送下一个请求。但是在 HTTP/2.0 中,你可以并发地发送多个 HTTP 请求,这些请求被并发地处理。
cookie HTTP 协议是无状态的,这意味着每个请求都是独立的,服务器默认情况下无法知道两个请求是否来自同一客户端或用户。Cookie 的引入使得服务器能够跨多个请求“识别”和“记住”用户。
HTTP 服务器通过 Set-Cookie 首部字段来设置每一个客户端的 Cookie 值,相应的 HTTP 响应的部分内容如下所示:
HTTP/1.1 200 OK
Set-Cookie: sessionId=abc123; Expires=Wed, 21 Oct 2025 07:28:00 GMT; Path=/; Secure; HttpOnly
当浏览器接收到带有 Set-Cookie 字段的 HTTP 响应时,就会在存储该 Cookie 字段,并在下次向对应的服务器发送 HTTP 请求时自动将 Cookie 字段添加在 HTTP 首部,之后的 HTTP 请求的部分内容如下所示:
GET /dashboard HTTP/1.1
Cookie: sessionId=abc123
当 HTTP 服务器接收到带有 Cookie 的请求时,它就可以区分这个请求是来自于那个客户端的了。